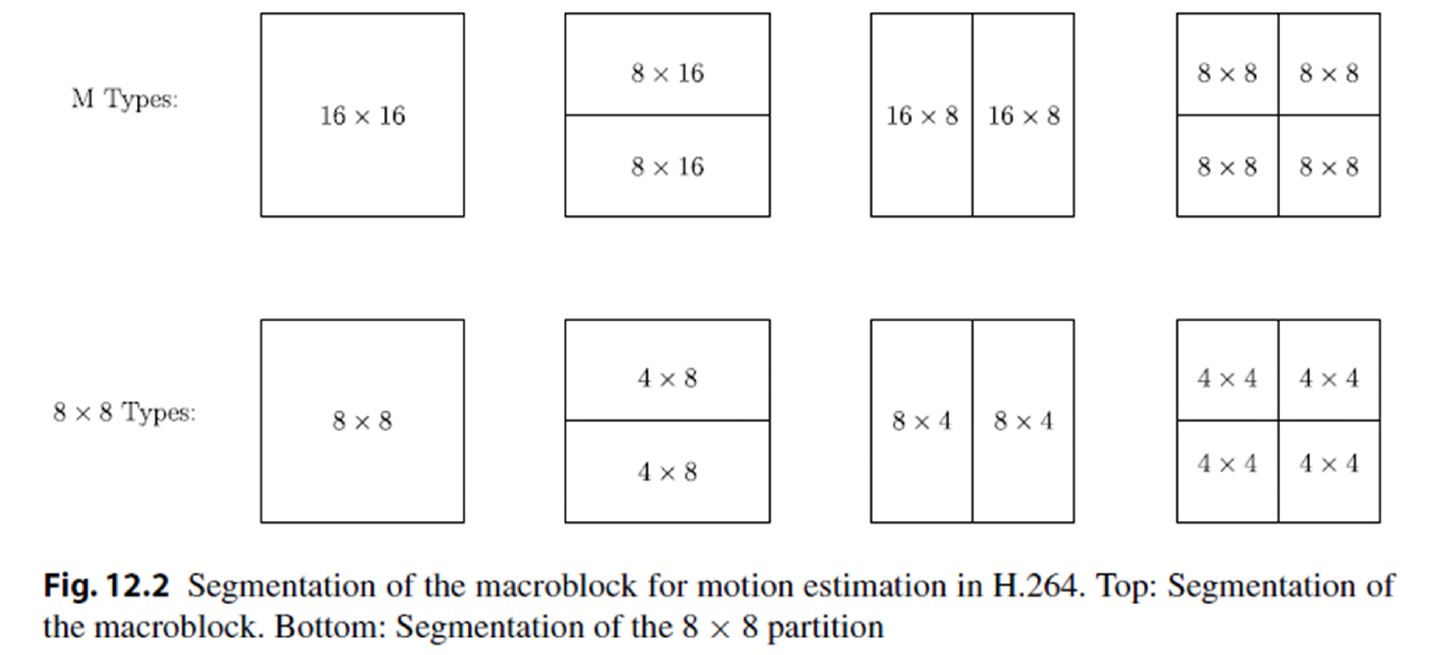
聚类分析
介绍
到目前为止,我们假设使用的训练样本是标记数据。使用标记数据的程序被称为监督学习。现在我们将探索使用未标记样本的无监督学习。
无监督学习不需要监督标记的训练数据集,因此它是一种理想的机器学习技术,可用于发现数据背后的模式和分组。无监督学习主要涉及两个主题:聚类分析和关联分析。本课程将重点介绍聚类分析,该分析已广泛应用于市场细分、搜索结果分组等。
聚类分析基础
粗略地说,聚类过程以具有很强内部相似性的数据点的聚类或分组的形式产生数据描述。正式的聚类过程使用标准函数并寻求优化标准函数的分组。
相似度测量
一旦我们将聚类问题描述为在一组数据中寻找自然分组的问题,我们就需要定义:
- 自然分组是什么意思?
- 在什么意义上,一个簇/组中的样本比其他簇中的样本更相似?
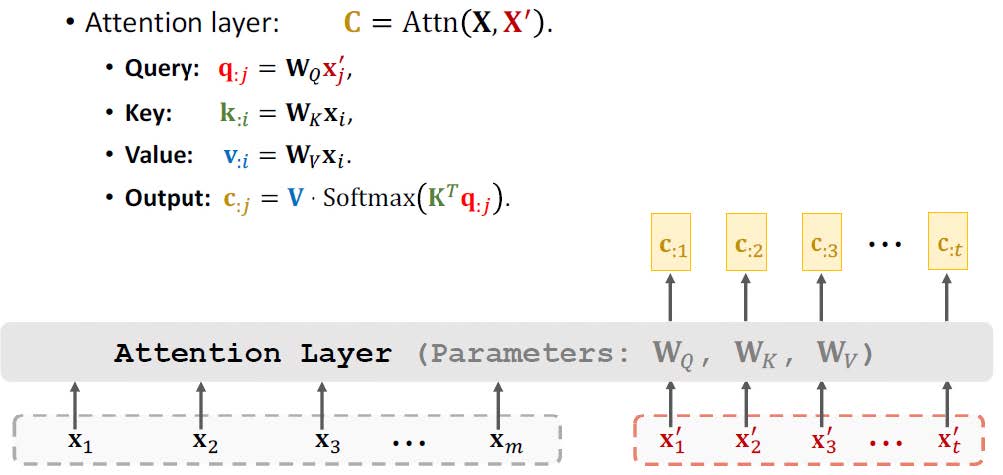
两个样本之间的相似性最明显的衡量标准是它们之间的距离。预计同一簇中的样本之间的距离明显小于不同簇中的样本之间的距离,如下所示。
一大类距离度量具有以下形式:
\[ d(\mathbf x,\mathbf x')=\left(\sum_{i=1}^d\left\lvert x_i-x_i'\right\rvert^q\right)^\frac1q \]
其中\(q\geq1\)是可选参数。这种距离度量称为闵可夫斯基距离。
如果\(q=2\),则距离度量是常用的欧几里得距离。
如果\(q=1\),则距离度量称为曼哈顿或城市街区距离。
也可以使用一些其他距离度量,例如Mahalanobis距离和余弦相似度度量。
聚类算法的类型
聚类算法有多种类型,包括
- 基于质心的聚类(分区方法)
- 层次聚类
- 基于分布的聚类
- 基于密度的聚类
基于质心的聚类
基于质心的方法也称为分区方法。它是一种将数据划分为非层次组的聚类方法。分区聚类最常见的例子是 K-Means聚类算法。
层次聚类
层次聚类可以作为分区聚类的替代方案,因为不需要预先指定要创建的聚类数量。在此技术中,数据集被划分为聚类以创建树状结构,也称为树状图。
基于分布的聚类
在基于分布的聚类方法中,数据是根据数据集属于特定分布的概率进行划分的。分组是通过假设某些分布(例如高斯分布)来完成的。
此类型的例子是高斯混合模型(GMM)。
基于密度的聚类
基于密度的聚类方法将密度高的区域连接成簇,只要密集区域能够连接起来,就可以形成任意形状的分布。
该算法通过识别数据集中的不同聚类并将高密度区域连接成聚类来实现这一点。数据空间中的密集区域被稀疏区域相互划分。
如果数据集的密度各不相同且维度较高,算法在对数据点进行聚类时可能会遇到困难。
基于质心的聚类
基于质心的聚类被认为是最简单但最有效的聚类算法之一。基于质心的聚类背后的直觉是,一个聚类由一个中心向量来表征和表示,而靠近这些中心向量的数据点被分配到相应的聚类中。
k-Means聚类算法
K 均值聚类是最流行的基于质心的方法。
假设我们有一组\(n\)个样本,\(\mathbf x_1,\mathbf x_2,\cdots,\mathbf x_n\),我们希望将其划分为恰好\(k\)个不相交的子集\(D_1,D_2,\cdots,D_k\)。每个子集代表一个聚类,同一聚类中的样本在某种程度上比不同聚类中的样本更相似。
那么问题就是找到使标准函数极值的分区。接下来,我们研究标准函数的特征,然后研究如何找到最佳分区。
聚类内平方和标准 (WCSS)
K-Means聚类采用聚类内平方和 (WCSS) 作为标准。设\(n_i\)为\(D_i\)中的样本数,设\(\mathbf m_i\)为这些样本的平均值:
\[ \mathbf m_i=\frac1{n_i}\sum_{\mathbf x\in D_i}\mathbf x \]
然后,聚类内平方和 (WCSS) 定义为:
\[ \text{WCSS}=\sum_{i=1}^k\sum_{\mathbf x\in D_i}\lVert\mathbf x-\mathbf m_i\rVert^2 \]
该标准函数有一个简单的解释:对于给定的聚类\(D_i\):均值向量\(\mathbf m_i\)是\(D_i\)中样本的最佳代表,因为它最小化了\(D_i\)中“误差”向量\(\mathbf x-\mathbf m_i\)的平方和。因此,WCSS测量用\(k\)个聚类中心\(\mathbf m_1,\mathbf m_2,\cdots,\mathbf m_k\)表示\(n\)个样本\(\mathbf x_1,\mathbf x_2,\cdots,\mathbf x_n\)所产生的总平方误差。
WCSS的值取决于样本如何分组到簇中以及簇的数量。最佳分割定义为最小化WCSS的分割。
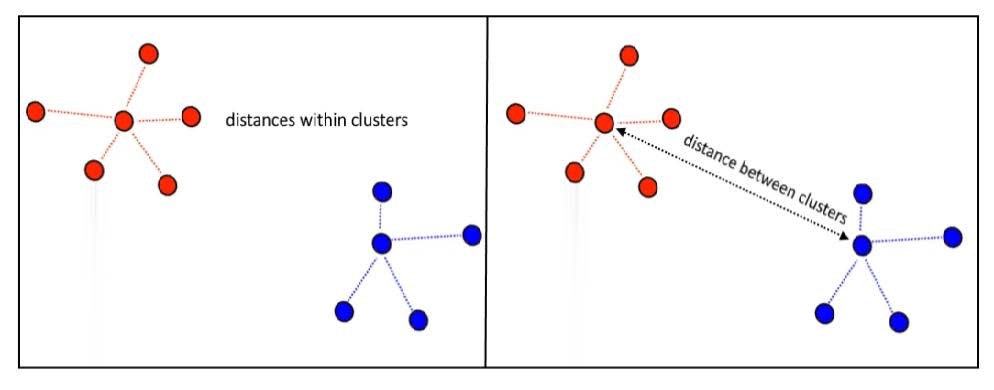
什么样的聚类问题适合WCSS标准?基本上,当聚类形成紧密的云并且彼此分离得相当好时,这是一个合适的标准,如下所示。
k-Means聚类算法由两个主要操作的迭代组成:
- 将样本分配到最近的聚类
- 计算新的聚类中心(质心)
k-Means聚类算法总结如下:
- 步骤 1:设置数字\(k\)来决定聚类的数量。
- 步骤 2:随机生成\(k\)个点或质心作为初始聚类中心。它们也可以从数据中随机选择。
- 步骤 3:将每个数据点分配到它们最近的质心,这将形成预定义的\(k\)聚类。
- 步骤 4:计算每个聚类的新质心。
- 步骤 5:重复步骤 3-4,直到质心和样本分配不再发生变化。
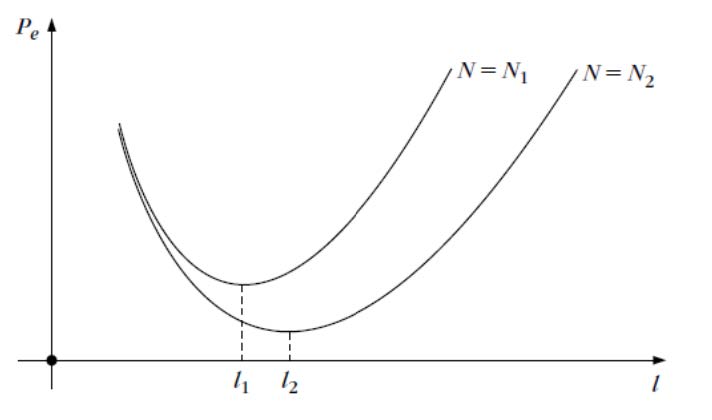
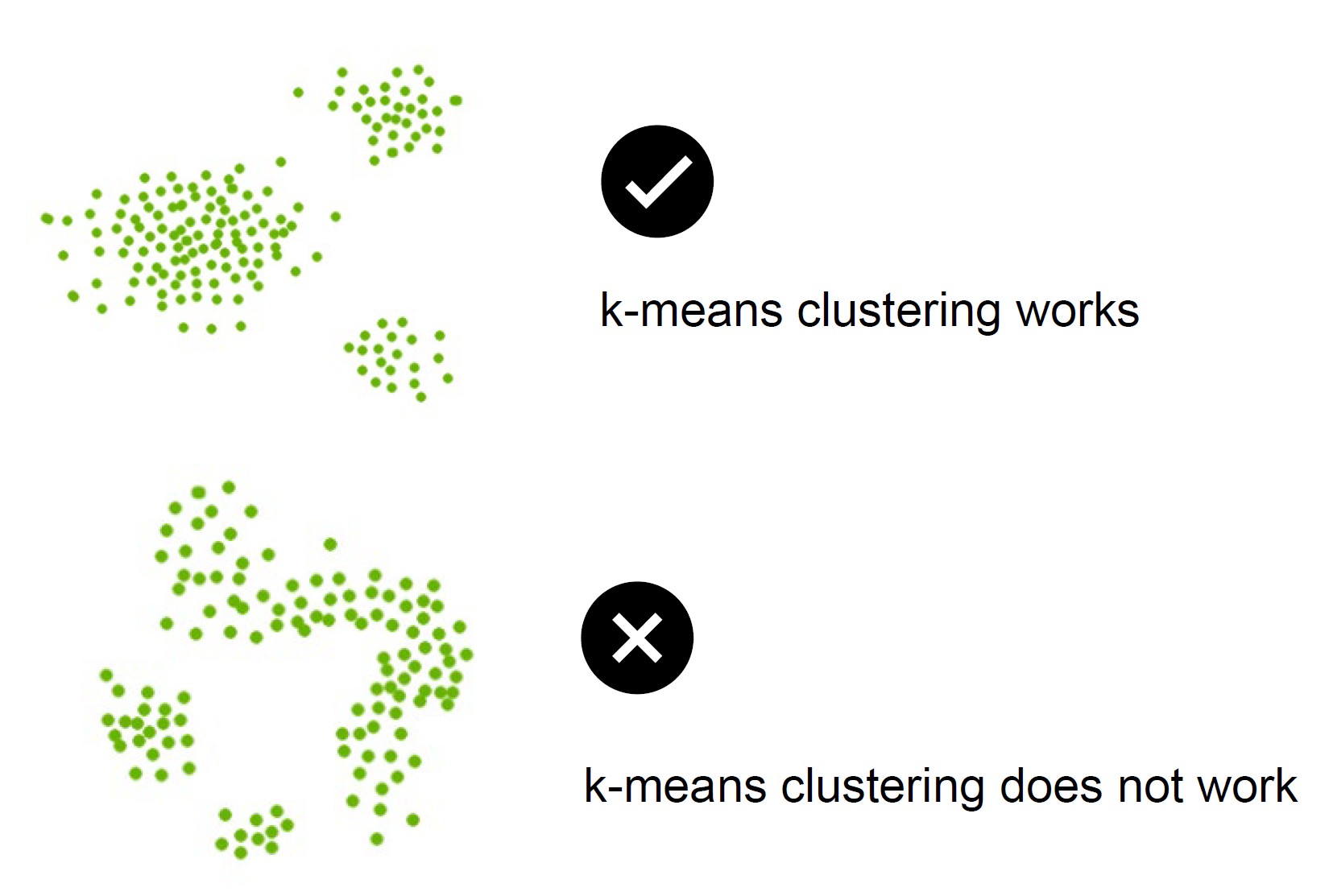
如何选择k-Means聚类中的\(k\)值?
肘部法是查找最佳聚类数的最流行方法之一。此方法使用WCSS,它定义了聚类内总的变化
为了找到聚类的最佳值,肘部法遵循以下步骤:
- 对给定数据集执行不同k值的k-Means聚类
- 对于每个k值,计算WCSS值。
- 绘制WCSS值与k值的曲线
- 图的弯曲尖点被视为k的最佳值。
层次聚类
这两个EE6483都讲过了……
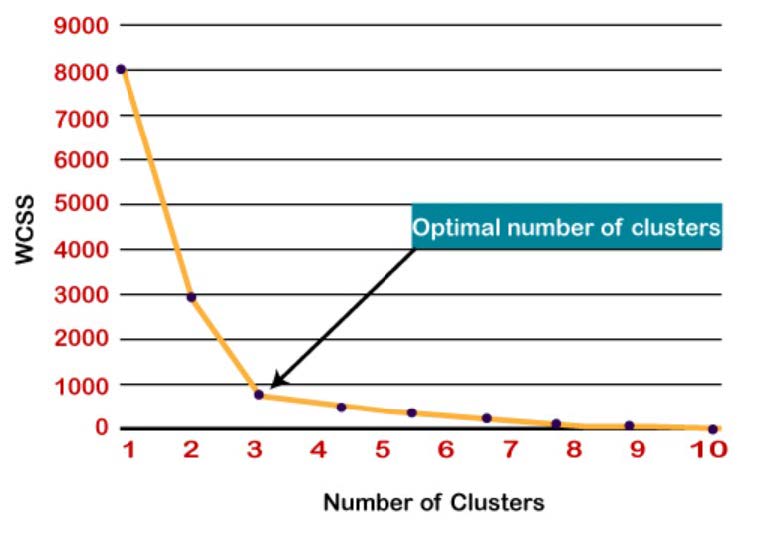
层次聚类是概括数据结构属性最常用的方法之一。层次树是样本划分的嵌套集合,用树形图或树状图表示,如下图所示:
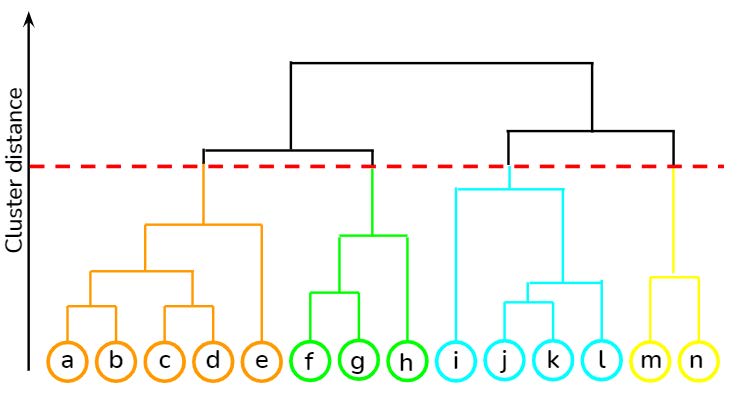
有几种不同的算法可用于查找层次树:
- 聚合算法,也称为自下而上的方法,从\(N\)个子簇开始,每个子簇只有一个样本,然后依次聚合成对的簇,直到所有簇都合并为一个包含所有样本的簇
- 分裂算法,也称为自上而下的方法,从包含所有样本的单个簇开始,然后依次拆分簇,直到每个子簇只包含一个样本。
层次聚类的优点是它不需要我们指定簇的数量,这与\(k\)均值聚类算法不同。
基于分布的聚类
在现实生活中,许多数据集可以用高斯分布(单变量或多变量)建模。因此,假设数据来自不同的高斯分布是非常自然和直观的。因此,我们可以尝试将数据集建模为几种高斯分布的混合。这是高斯混合模型(GMM)的核心思想。
在监督学习中,GMM用于对类条件概率密度函数进行建模。在这里,它用于无监督学习中的聚类。
假设数据底层有\(m\)个聚类,每个聚类中的数据服从正态(高斯)分布。那么数据的分布可以建模为:
\[ p(\mathbf x)=\sum_{i=1}^m\alpha_iN(\mathbf x\vert\mu_i,\Sigma_i) \]
其中\(\mu_i\)和\(\Sigma_i\)分别是第\(i\)个高斯分量(即聚类)的均值向量(即聚类中心)和协方差矩阵。\(\alpha_i\)是第\(i\)个高斯分量的权重,
\[ \sum_{i=1}^m\alpha_i=1 \]
GMM模型参数可以使用期望最大化 (EM) 算法进行估计。有关基于EM的GMM模型参数估计的详细信息,请参阅第 3 部分的讲义。
- 步骤 1:设置数字\(m\)来决定聚类的数量。
- 步骤 2:用随机值初始化\(\hat\alpha_i(0)\),\(\hat\mu_i(0)\),\(\hat\Sigma_i(0)\)
- 步骤 3:使用期望最大化算法估计高斯混合模型的参数。
- 步骤 4:高斯分量的均值向量是聚类中心。将每个数据点分配给其最近的聚类中心。
基于密度的聚类
K-Means和层次聚类非常适合寻找球形聚类或凸聚类。换句话说,它们仅适用于紧凑且分离良好的聚类。
但许多真实的数据集可能包含不规则现象,例如:
- 任意形状的簇
- 带有噪声的数据。
基于密度的聚类可以解决这些问题。基于密度的噪声空间聚类(DBSCAN)聚类方法是目前最流行的基于密度的聚类方法。
DBSCAN算法基于“聚类”和“噪声”的直观概念。
簇是数据空间中的密集区域,由密度较低的点区域分隔。对于簇中的每个点,给定半径的邻域必须至少包含最小数量的点。
相比之下,密度较低的区域的点则被视为噪声。这与k均值聚类非常不同,在k均值聚类中,每个数据点都被分配到一个聚类中。
DBSCAN 算法使用两个参数:
- MinPts:聚集在一起的点的最小数量(阈值),使某个区域被视为密集。例如,MinPts=4 表示至少需要4个点才能形成一个密集的簇
- eps (\(\epsilon\)):一种距离测量,用于定位任何点邻域中的点,即,如果两点之间的距离低于或等于“eps”,则它们被视为邻居,即 \(\epsilon\) 邻域。
在这个算法中,我们有3种类型的数据点:
- 核心点:如果某个点在 \(\epsilon\) 范围内有超过 MinPts 个点,则该点为核心点。
- 边界点:\(\epsilon\) 范围内的点数少于 MinPts,但位于核心点的邻域内。
- 噪声或异常值:不是核心点或边界点的点
如果我们探索可达性和连通性两个概念,就能更好地理解这些参数。
可达性表示一个数据点是否可以直接或间接地从另一个数据点访问,而连通性表示两个数据点是否属于同一个簇。就可达性和连通性而言,DBSCAN 中的两个点可能是:
- 直接密度可达
- 密度可达
- 密度连通
如果点(或样本)p 位于核心点 q 的 \(\epsilon\) 邻域内,则 p 可以从点 q 直接密度到达
如果存在一组从 q 到 p 的核心点,则 p 从 q 密度可达。
如果存在一个核心点,且从该核心点出发两个点都是密度可达的,则称这两个点密度连通。
DBSCAN 的参数设置
MinPts
根据经验法则,可以从数据集的维数\(D\)中得出最小值,例如\(\text{MinPts}\geq D+1\)。MinPts的最小值必须至少为3
但是,对于有噪声的数据集,值越大越好,并且会产生更显著的聚类。根据经验,可以使用\(\text{MinPts}=2\cdots D\),但对于非常大的数据、噪声数据或包含许多重复项的数据,可能需要选择更大的值。
\(\epsilon\)
然后可以通过绘制与\(k=\text{MinPts}−1\)最近邻的距离(从最大值到最小值排序)来选择 \(\epsilon\) 的值。 \(\epsilon\) 的良好值是此图显示“肘部”(最大曲率)的位置。 通常,\(\epsilon\) 的值较小是可取的,并且根据经验法则,只有一小部分点应该在此距离内。
DBSCAN 通过检查数据集中每个点的 \(\epsilon\) 邻域来搜索数据集中的聚类。如果数据点的 \(\epsilon\) 邻域包含的邻居数量超过最小值 MinPts,则创建一个以点 p 为核心的新聚类。然后,该算法直接从这些核心点组装密度可达点,以合并所有密度可达聚类。
当没有新点可添加到任何组时,此过程终止。不属于任何聚类的点被视为噪声或异常值。
DBSCAN 算法
- 步骤 1 设置 MinPts 和 \(\epsilon\) 的值,并从数据集中随机选取一个数据点作为起点。
- 步骤 2 递归查找其所有密度连通点,并将它们分配到与核心点相同的簇中。
- 步骤 3 在前面步骤中未访问过的点中随机选择另一个点,然后转到步骤 2
- 步骤 4 当所有点都被访问后,此过程结束。不属于任何簇的点被视为噪声。
DBSCAN 的优点
- DBSCAN 算法对异常值(噪声点)具有很强的鲁棒性。
- DBSCAN 非常擅长将高密度簇与低密度簇分离。
- 与 K-means 不同,DBSCAN 不需要预先指定簇的数量。
- DBSCAN 支持具有不规则结构的簇。
DBSCAN 的缺点
- DBSCAN 不适用于密度不同的簇。
- DBSCAN 算法不是确定性的,因为它会在不同的试验中形成不同的簇。
- 有时,选择 \(\epsilon\) 的值可能很困难,尤其是当数据处于较高维度时。