人工智能模型与架构
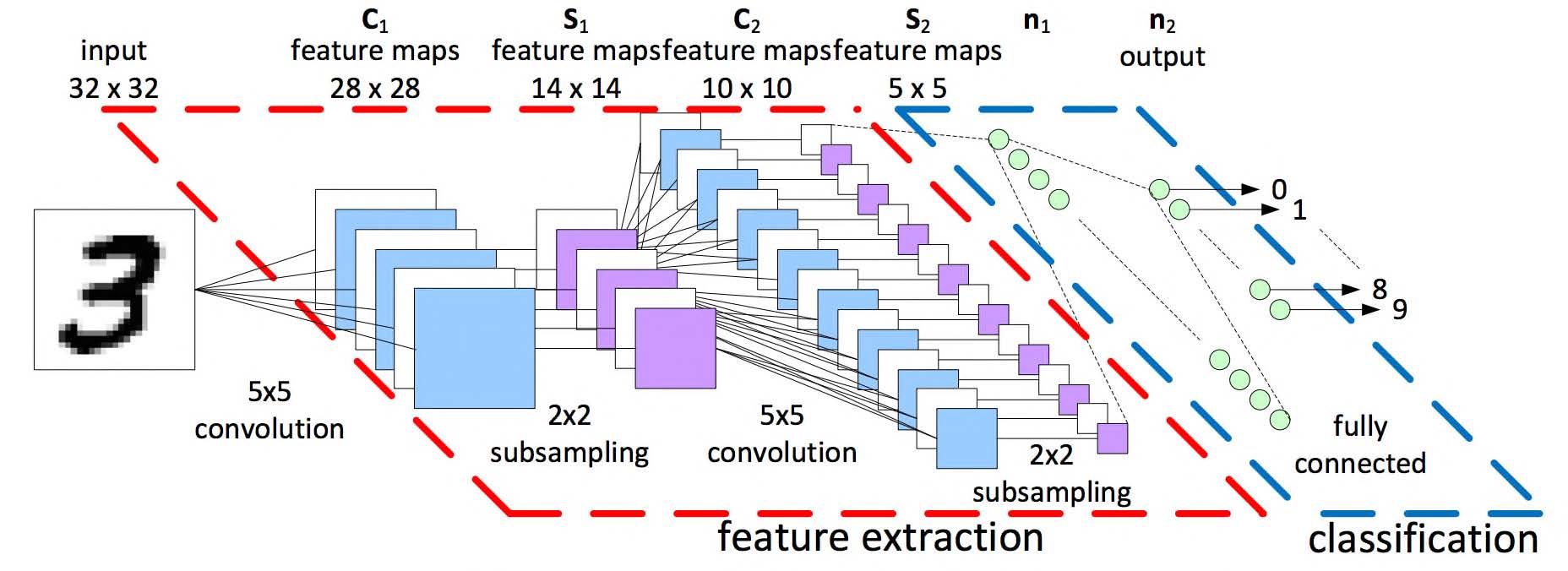
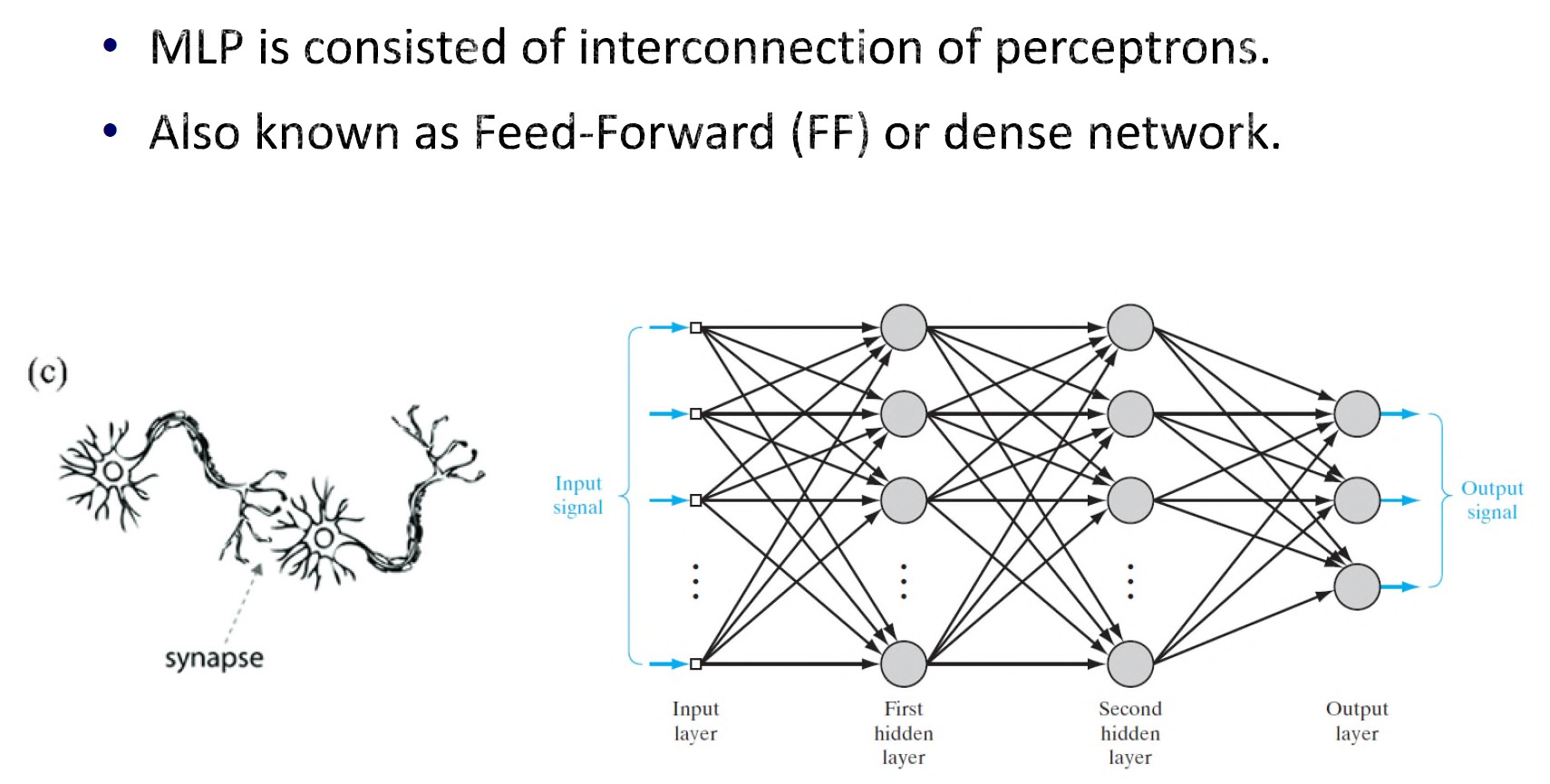
卷积神经网络 (CNN)
简介
- 由深层组成,以逐步提取更高级别的抽象特征。
- 常用于分类和回归应用。
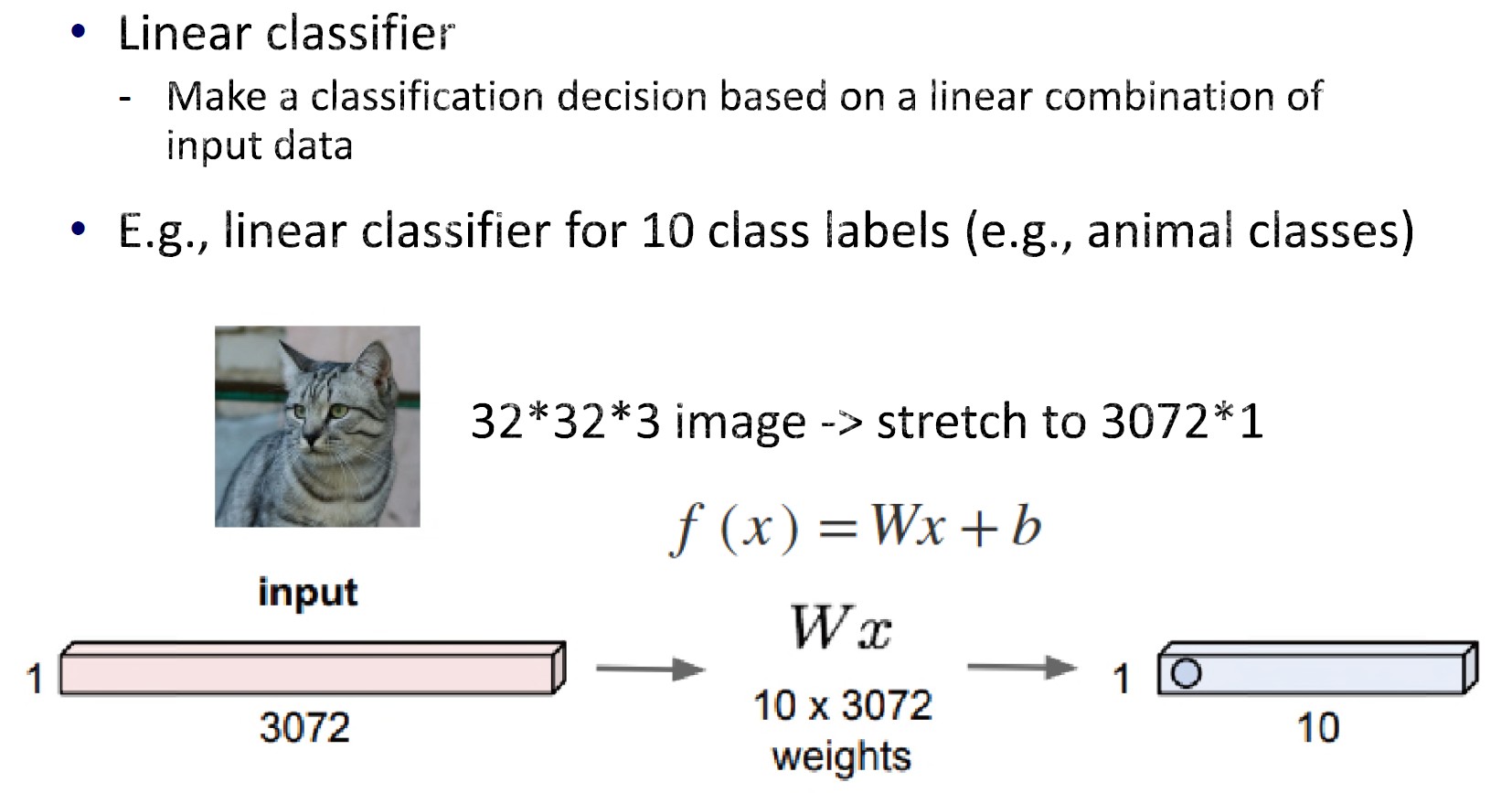
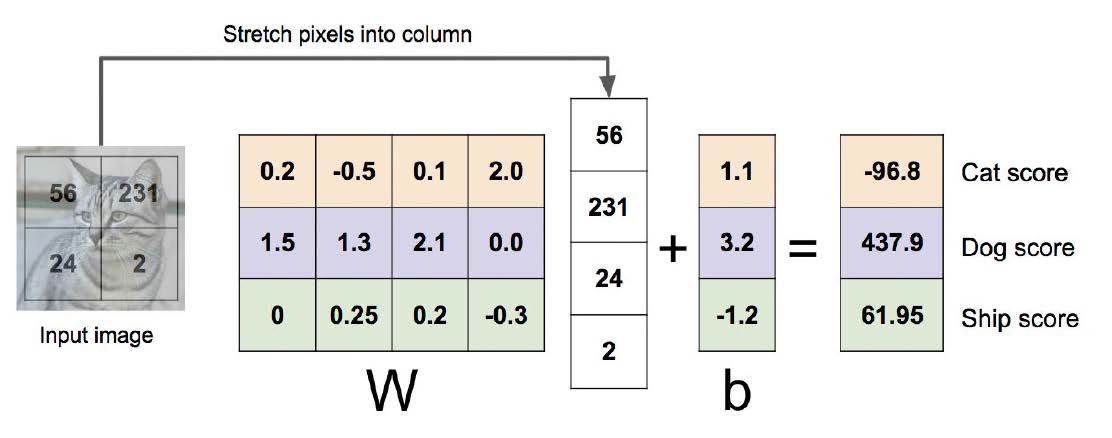
线性分类器
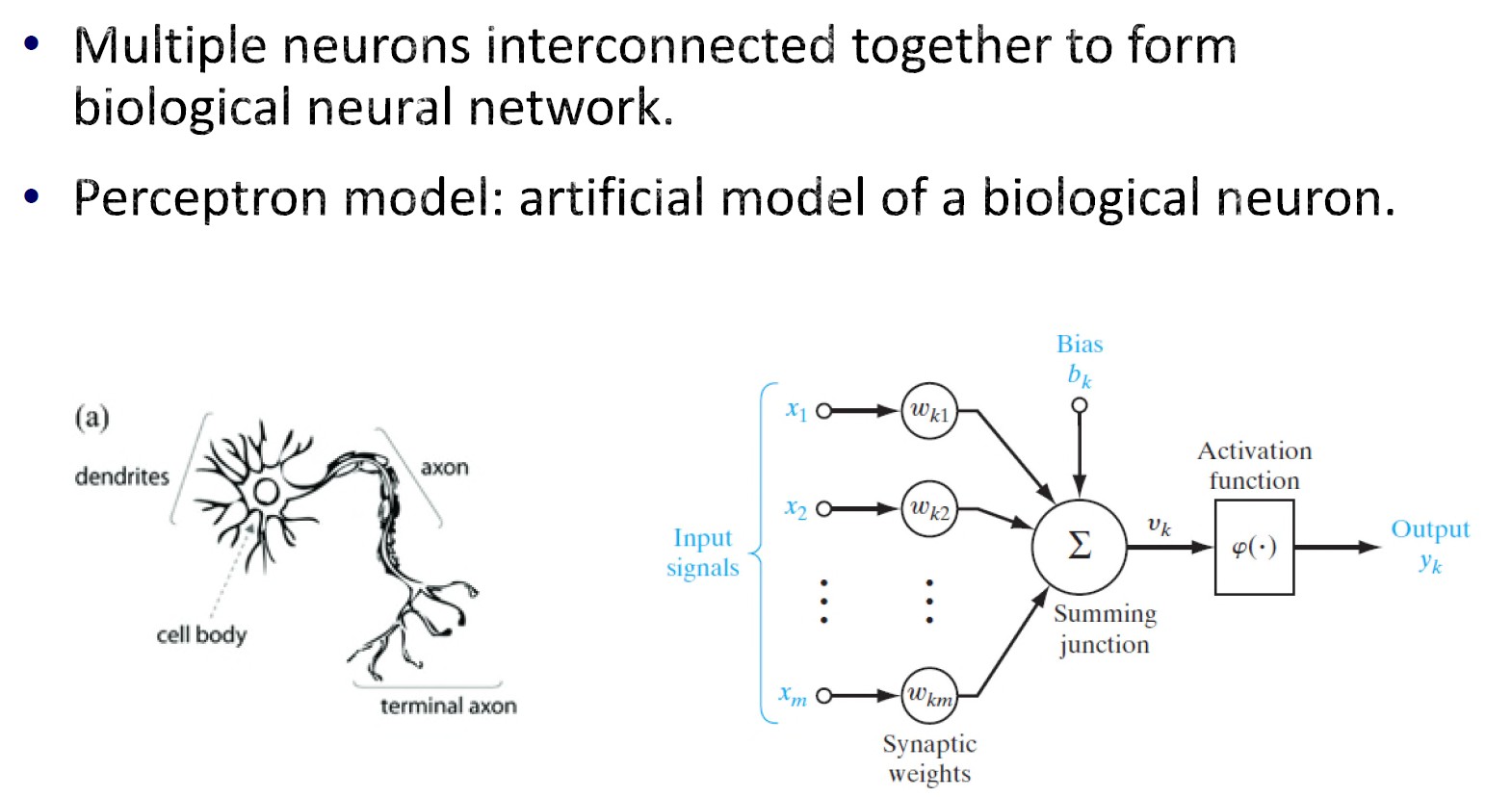
大脑视觉皮层:大脑皮层的主要区域,接收、整合和处理从视网膜传递的视觉信息。
损失函数
我们如何确定W和b?
我们需要一个损失函数(误差测量),它是训练期间预测值和输出目标值(教师)之间的度量/距离。
损失函数取决于我们要解决的问题类型。
两个常见问题:
- 回归
- 目标输出是连续值。
- 例如,股价预测、降雨量估计等。
- 分类
- 预测输入的标签/类别。
- 目标输出是离散的(来自一组可能的标签)。
- 例如,癌症分类(二进制)、人脸识别(多类)。
- 回归
常用回归损失函数
- 平方损失:
\[ L(x,y)=\sum_i(y_i-f(x_i))^2 \]
- 均方误差 (MSE):
\[ \mathrm{MSE}=\frac1N\sum_i(y_i-f(x_i))^2 \]
- 平均绝对误差 (MAE):
\[ \mathrm{MAE}=\frac1N\sum_i\lvert y_i-f(x_i)\rvert \]
\(x\)和\(y\)是输入数据和目标输出值,\(f(x)\)是网络预测输出。
常用分类损失函数
- Softmax损失:具有softmax正则化的交叉熵损失。
\[ p_j=\frac{\mathrm e^{z_j}}{\sum_k\mathrm e^{z_k}},\ \text{where}\ z_j=f(x_j)\\ L=-\sum_jy_j\ln p_j \]

卷积神经网络 (CNN)
CNN架构
- 卷积层
- 激活函数层
- 池化层
- 全连接 (FC) 层 / 线性层
- Softmax层
卷积层
- 以分层方式提取特征。
- 前几层提取低级特征,而后几层提取高级特征。
- 通过卷积核共享权重来减少要训练的参数。

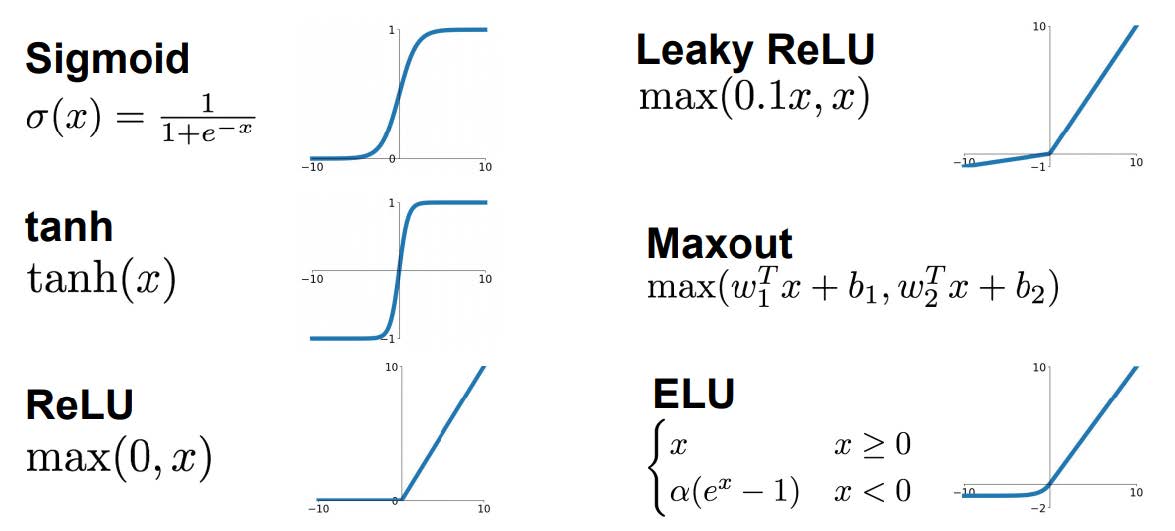
激活函数层
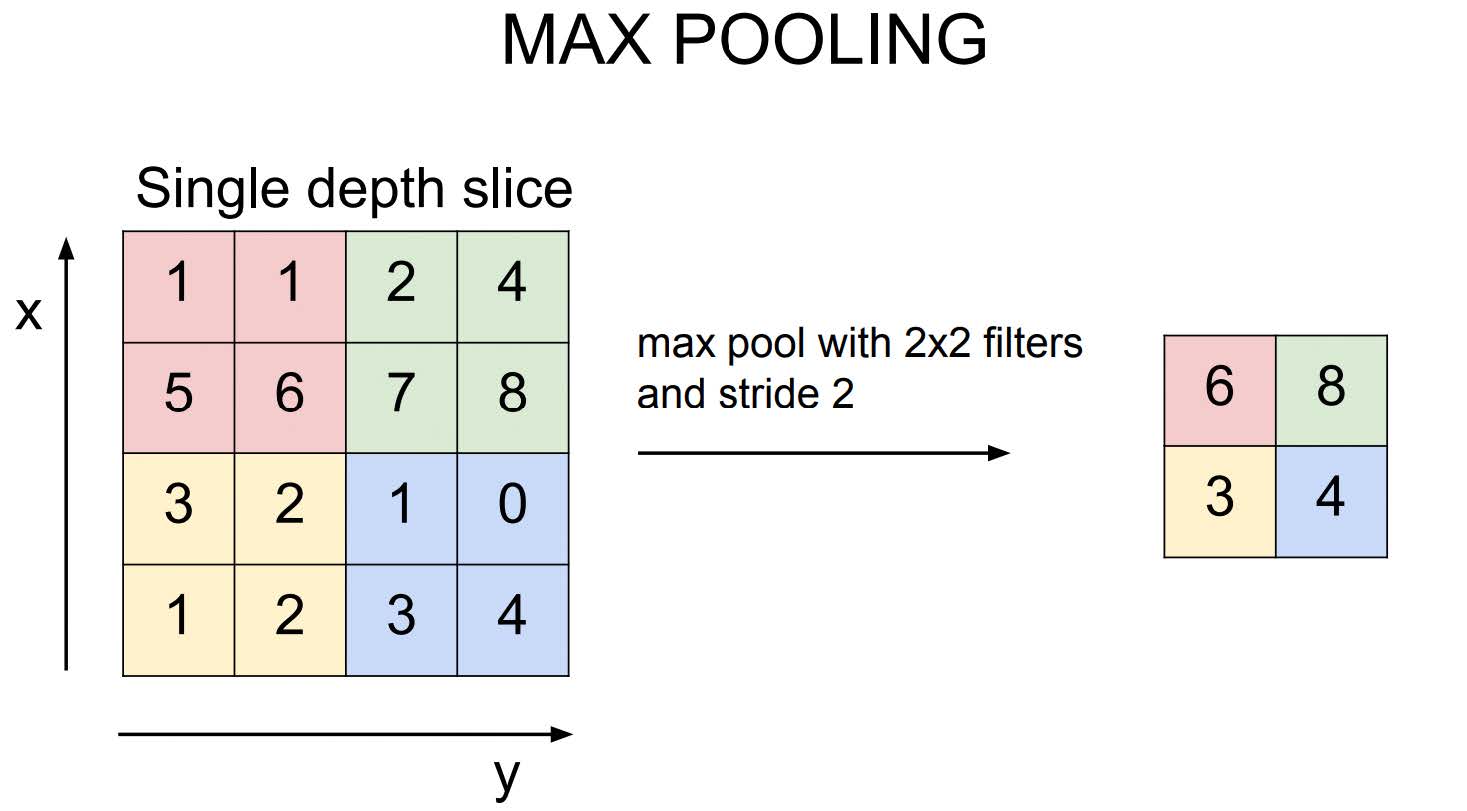
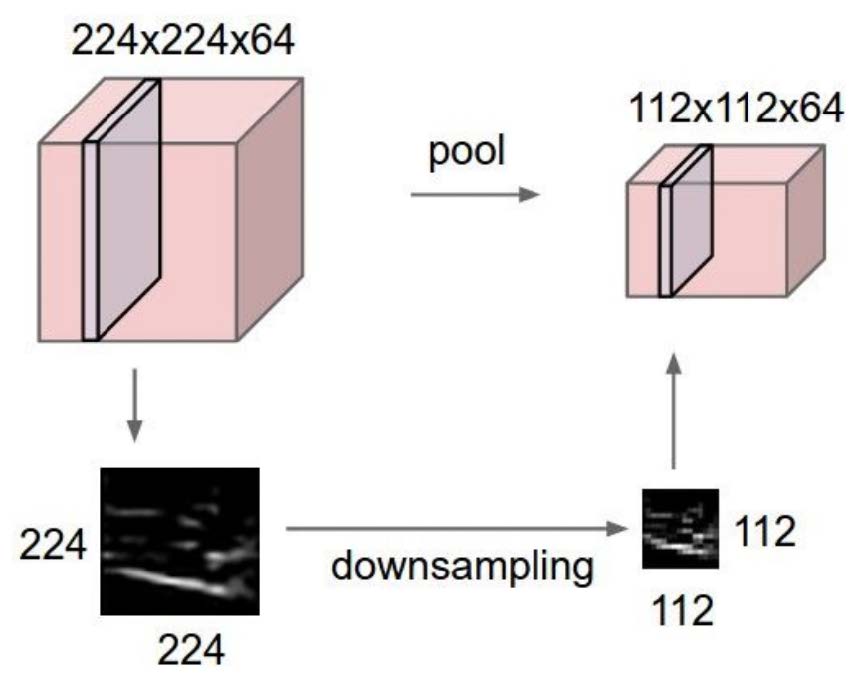
池化层
- 降低激活图维度,从而减少计算和存储需求。
- 常见池化操作:最大池化、平均池化。
- 激活图/特征图的每个通道独立运行。
Softmax层
- 将最后一层 FC 层的输出分数 (logits) 映射到分类问题的概率中。
- 根据概率计算 Softmax 损失。
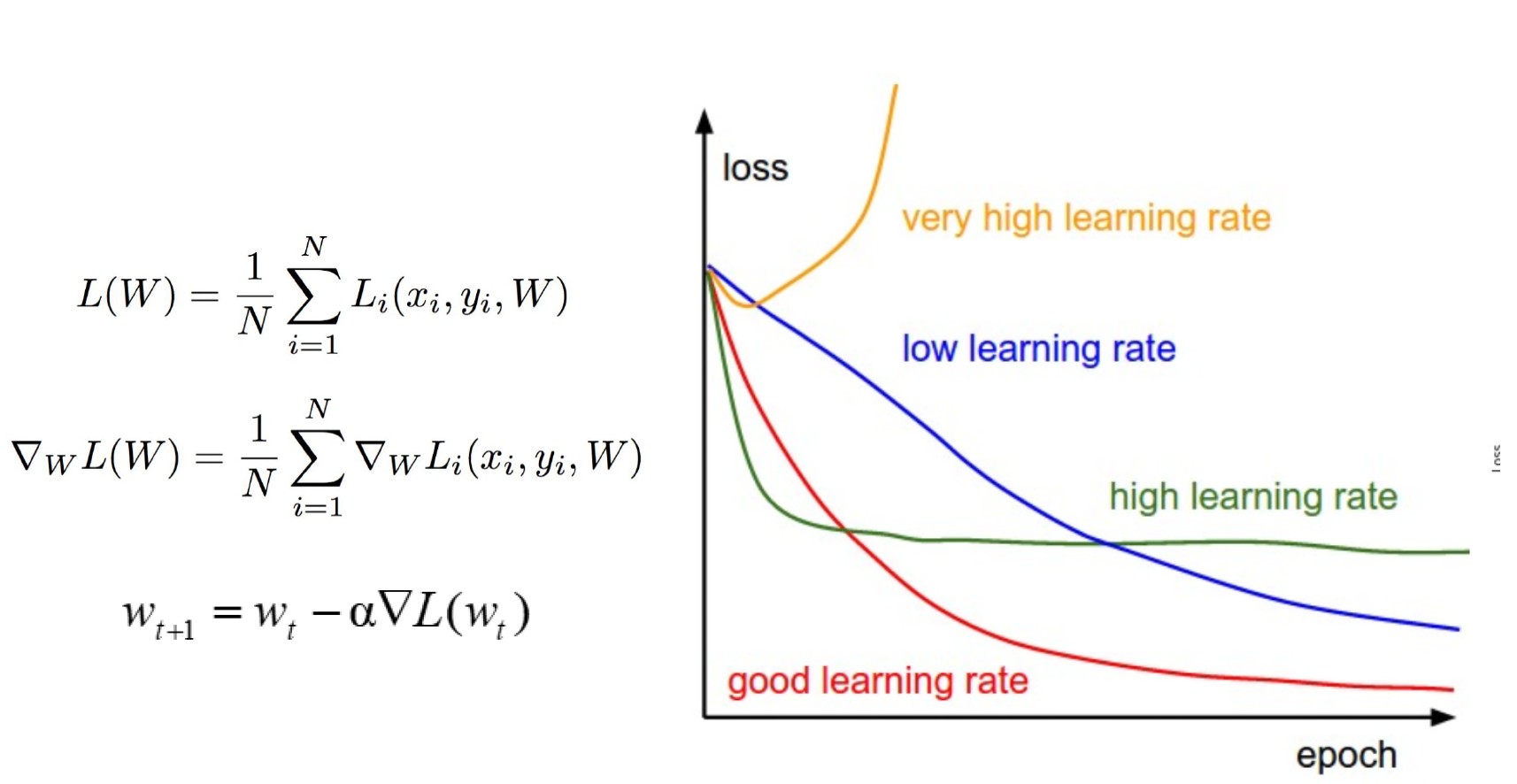
CNN 训练与优化
- 目标是最小化/优化损失函数。
- 常见策略以随机梯度下降 (SGD) 及其变体为中心。
- 使用计算图计算梯度下降和参数更新
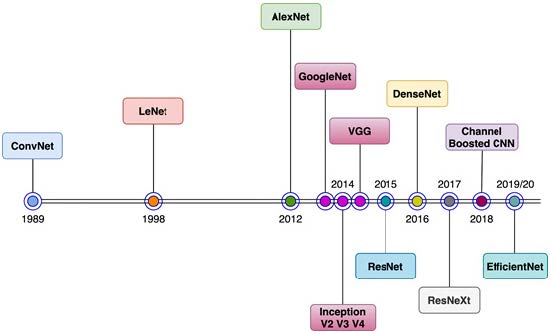
知名 CNN 架构
应用
循环神经网络 (RNN)和长短期记忆 (LSTM)
- 一种专门处理序列的神经网络。
- 常用于涉及时间序列和状态序列预测和建模的应用。
- 示例应用:股票价格预测、语言翻译。
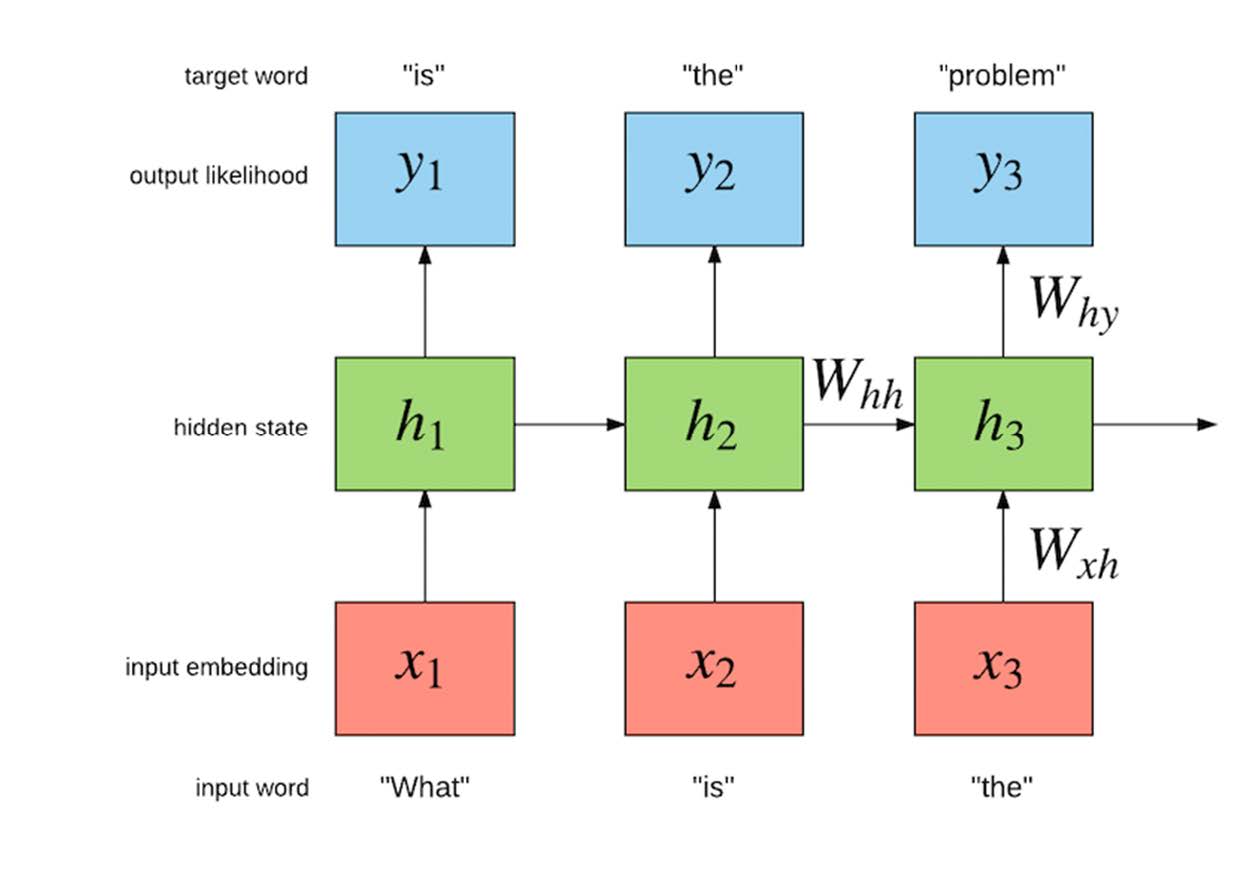
循环神经网络 (RNN)
- RNN 是一类神经网络,其输入形式为序列数据,例如时间序列数据。
- 常用于时间/序列数据的分析。
- 广泛应用于自然语言处理 (NLP)、机器翻译、图像字幕等应用。
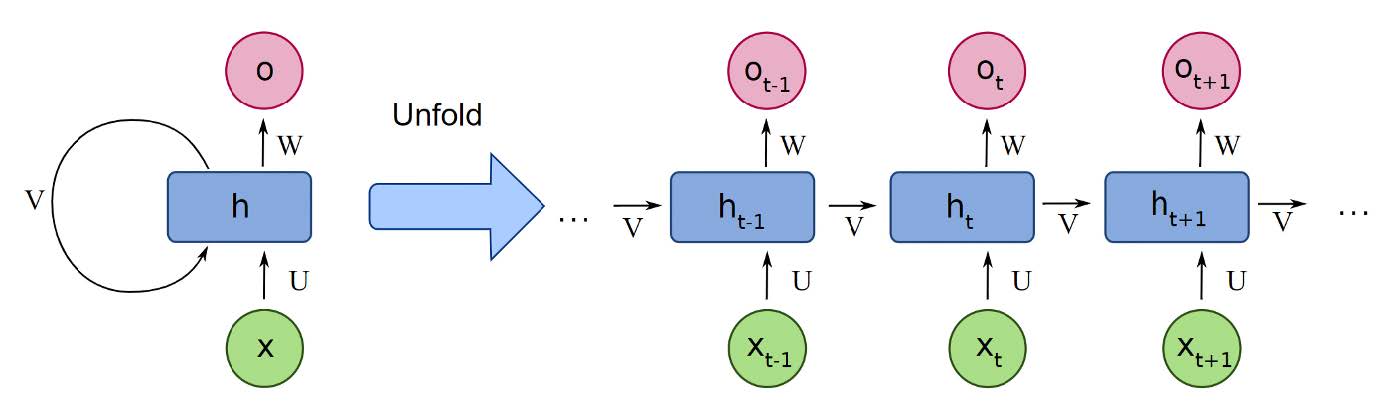
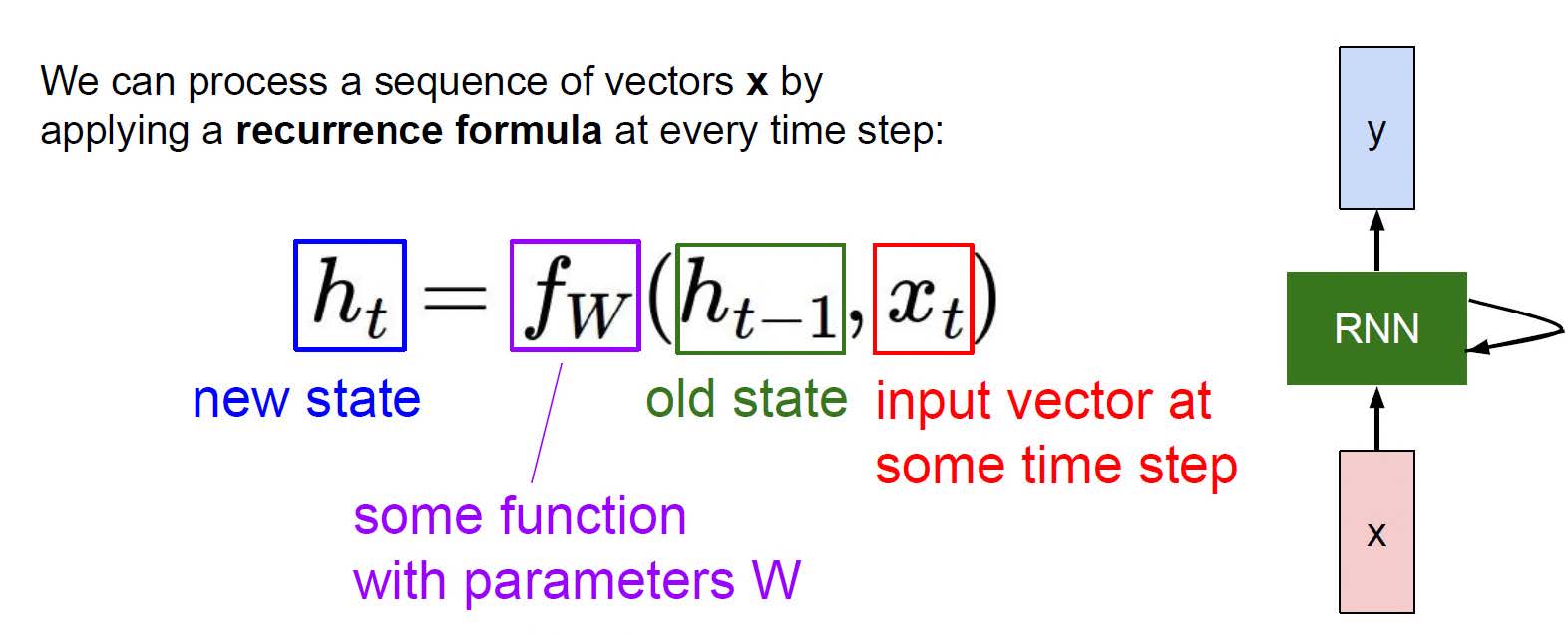
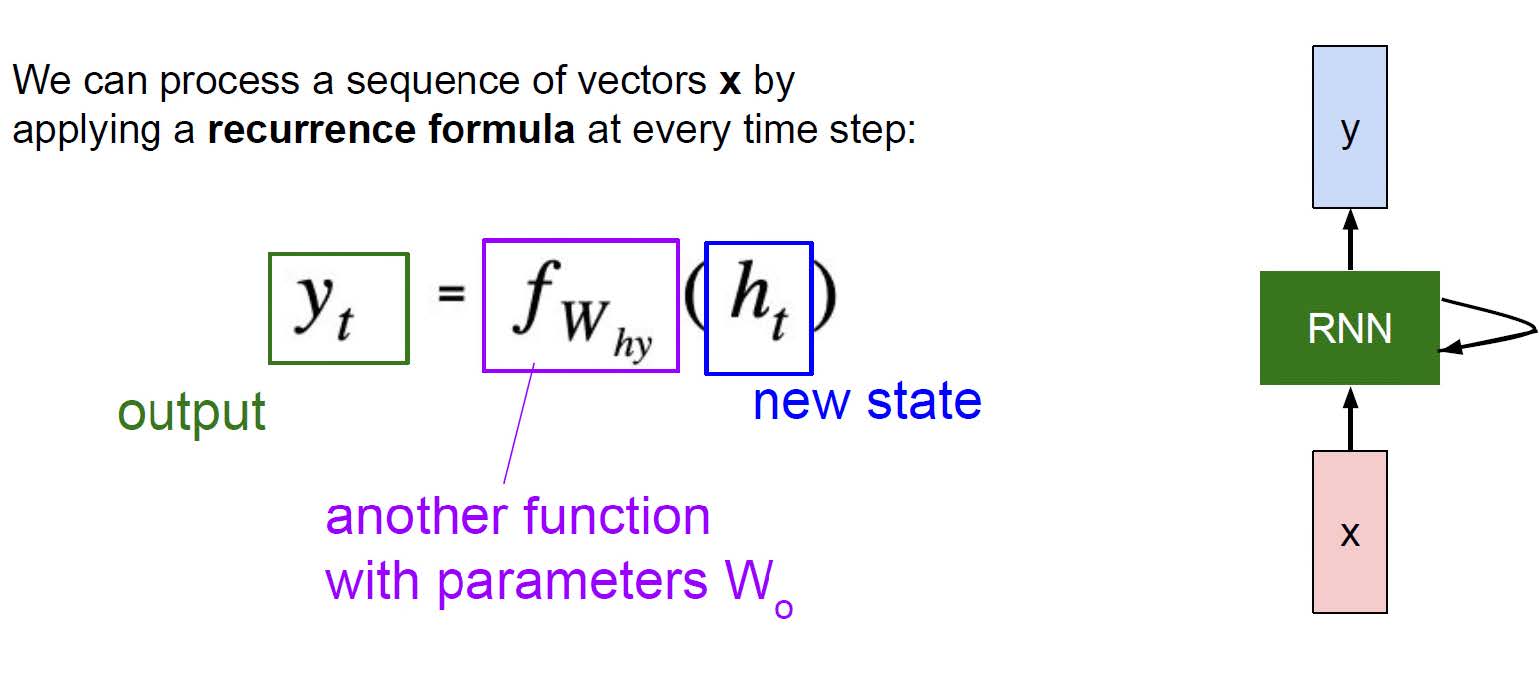
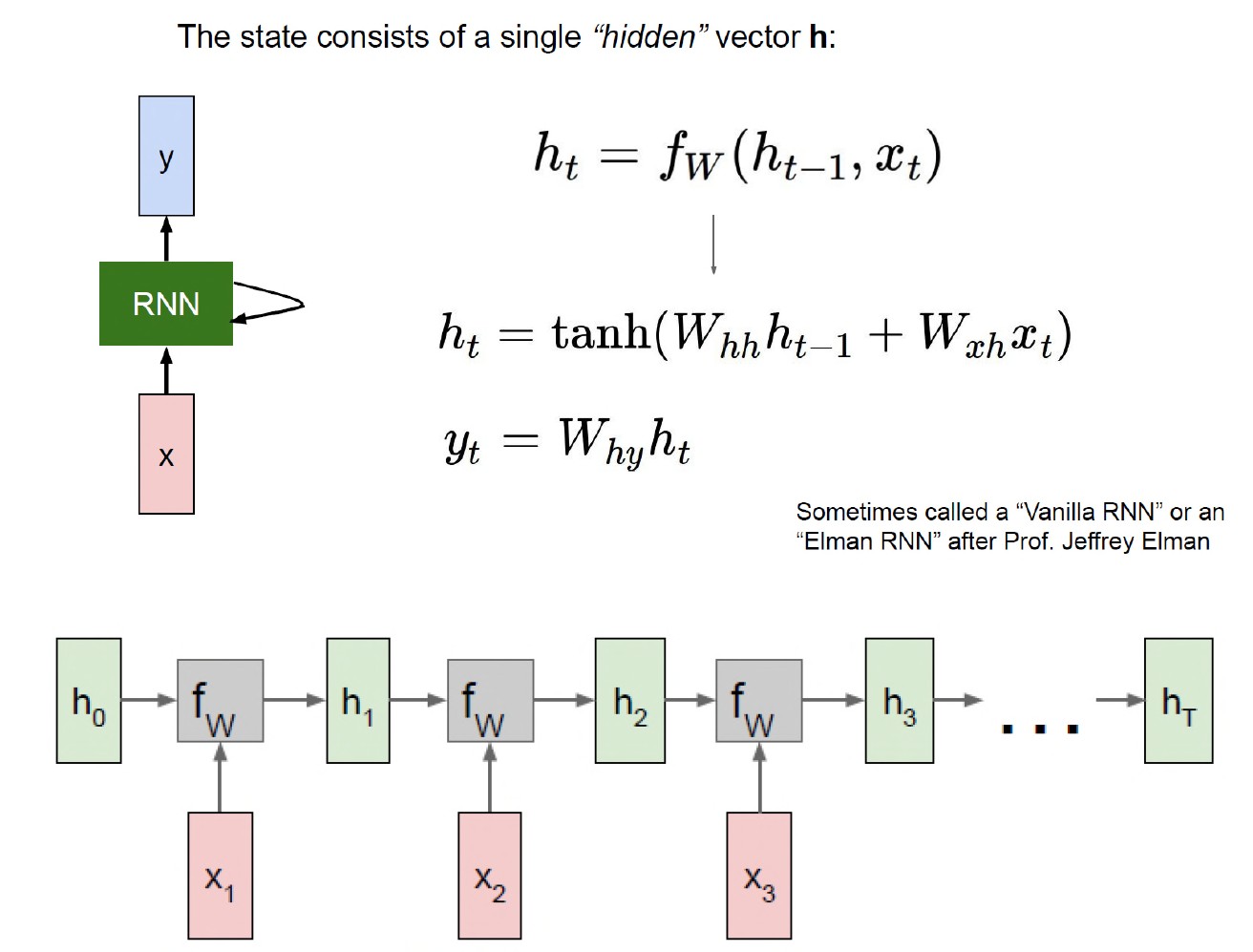
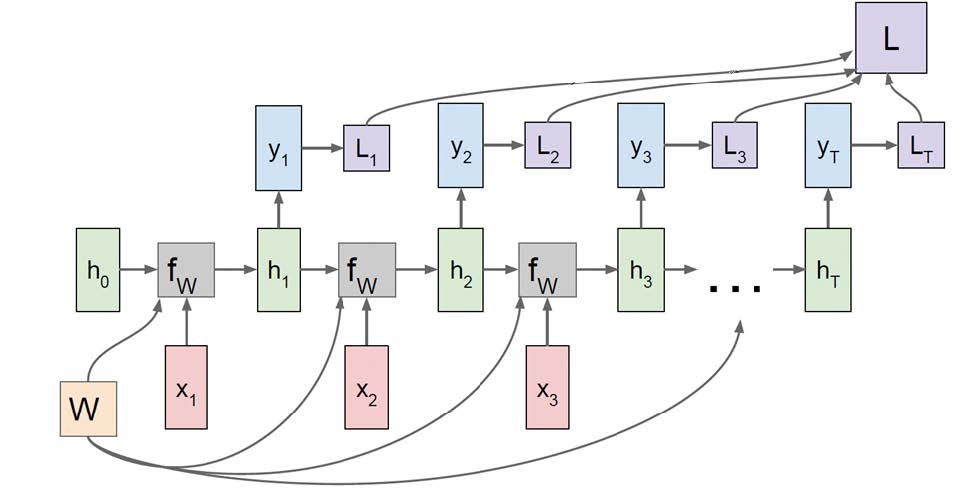
RNN 训练与优化
长短期记忆 (LSTM)
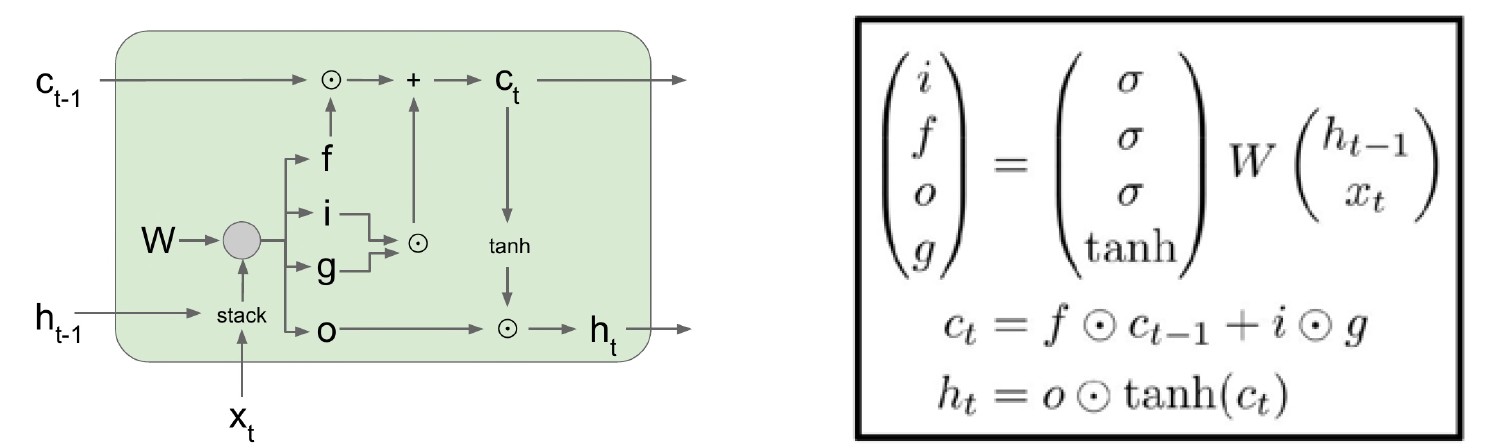
• 一个可以随时间维持其状态的记忆单元。 • 由单元状态 (\(c_t\))、隐藏状态 (\(h_t\)) 和 4 个门 (\(i\)、\(f\)、\(o\)、\(g\)) 组成。 • \(c_t\):长期记忆,\(h_t\):短期记忆。 • 单元状态 (\(c_t\)) 通过忘记旧记忆(通过忘记 (\(f\)) 门)和添加新记忆(通过输入 (\(i\)) 门和门 (\(g\)) 门)发生变化。 • 通过将单元状态 (\(c_t\)) 传递到输出门来更新隐藏状态 (\(h_t\))。 • 门控制信息流向记忆。 • 门通过 sigmoid/tanh 层获得,它们使用逐点乘法运算符更新 \(c_t\) 和 \(h_t\) 单元状态。
应用
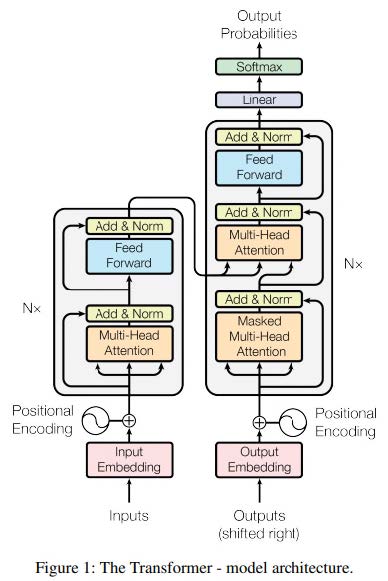
Transformer
- 一种使用注意力机制并行处理输入序列的网络。
- 擅长对长程依赖性进行建模。
- 在许多视觉和NLP应用中实现最先进的性能。

注意力机制用于确定哪些输入标记(例如,NLP 中的单词、CV 中的图像块)与当前输入/标记相关。
注意力机制通过两个向量之间的相关性(点积)计算得出。
相关性 -> 相似性/相关性/重要性 -> 注意力
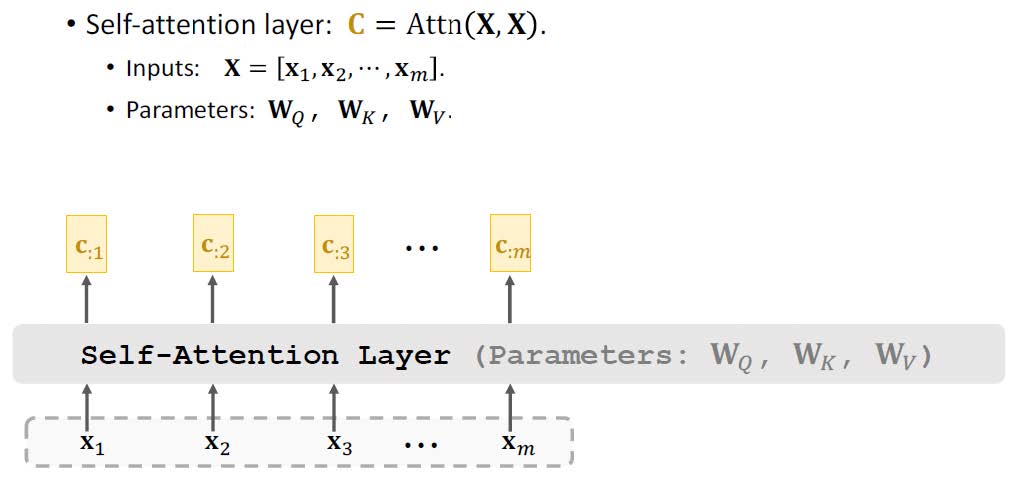
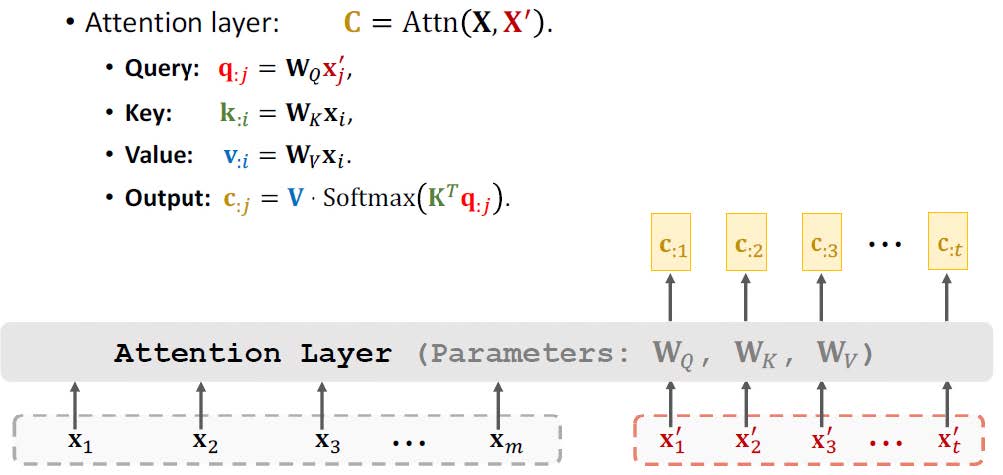
每个输入标记生成 3 个向量:查询 (q)、键 (k) 和值 (v)。这些向量通过线性映射 (WQ、WK、Wv) 提供更灵活的表示,以学习输入标记之间的潜在关系/注意力。
注意力使用以下方法计算:
- 步骤 1:计算查询 (q) 和键 (k) 向量之间的相关性 (点积)。
- 步骤 2:使用 Softmax 函数对步骤 1 中的相关值进行缩放和规范化。
- 步骤 3:将步骤 2 中的输出乘以相应的值 (v) 向量并将它们相加。

- Transformer 使用注意力机制并行处理输入序列。
- 使用注意力机制和密集/前馈/MLP 层。
- 高度可并行化。
- 可以提供全局注意力。
- 擅长建模长程依赖关系。
- 在许多视觉和 NLP 应用中实现最先进的性能。
- 引领其他 SOTA 方法,如 BERT:用于语言的深度双向 Transformer 的预训练。
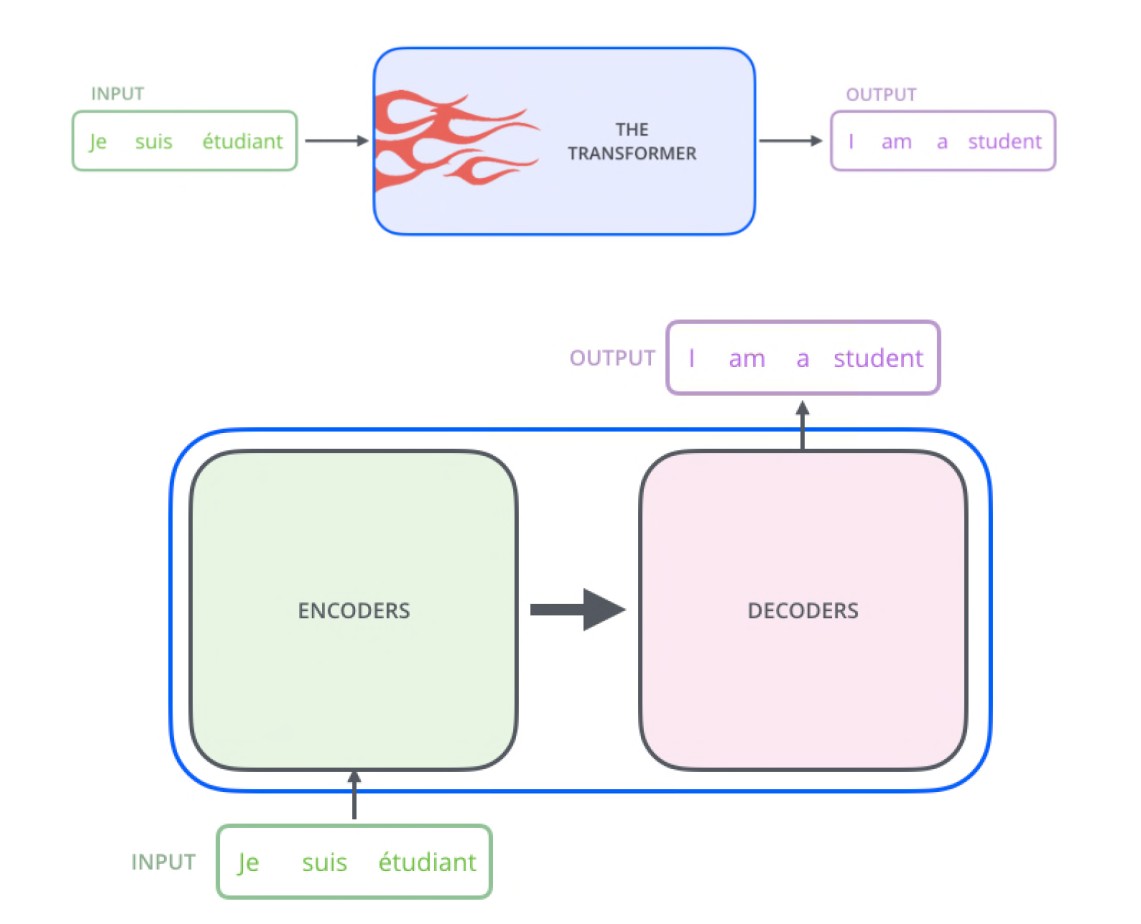
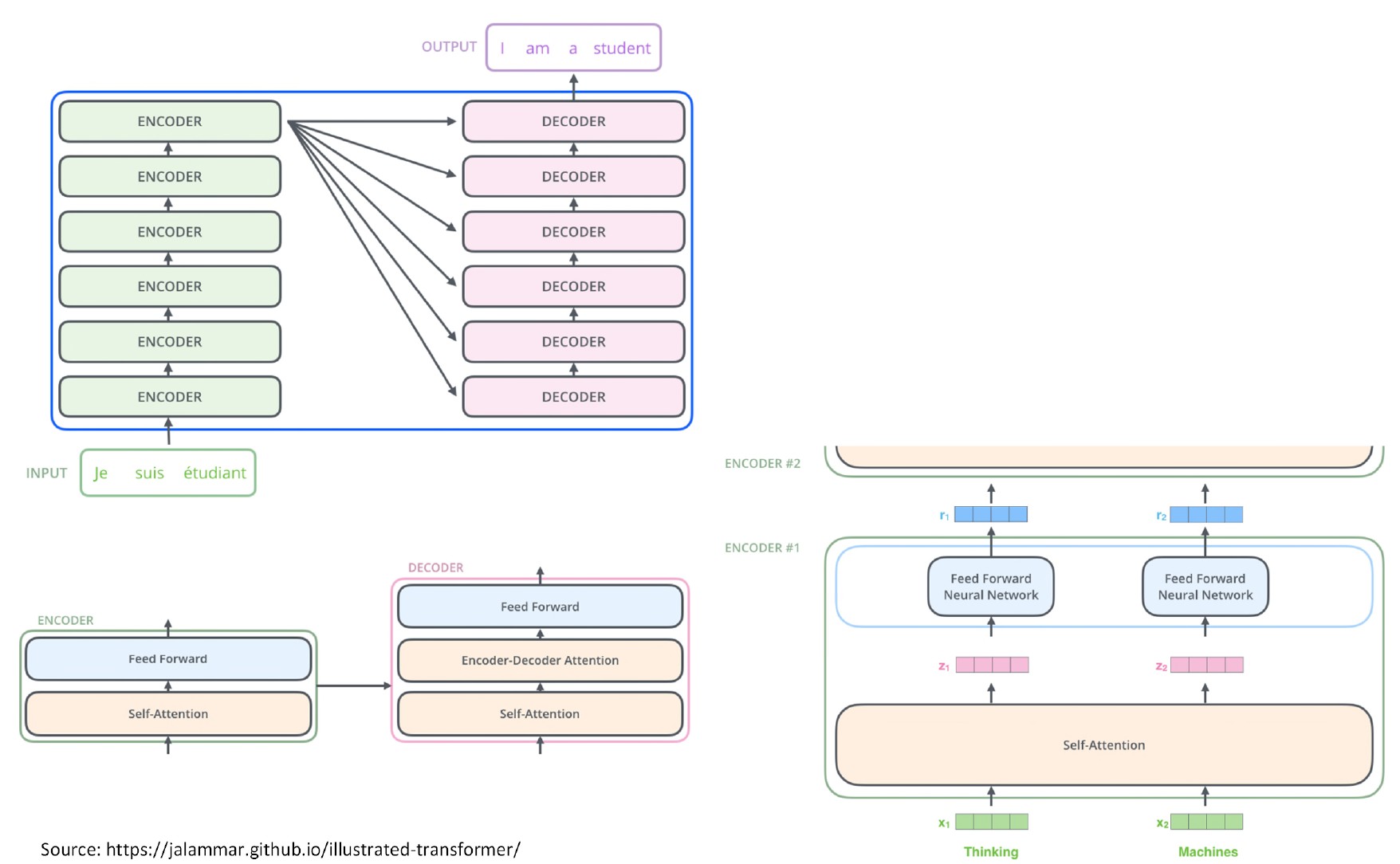
- 最初设计用于神经机器翻译。
- 后来扩展到视觉任务,如识别、检测等,并取得了巨大成功。
- 利用注意力机制来分析一个 token(单词/图像块)相对于其他 token/图像块的重要性。
- 由 transformer 编码器和 transformer 解码器组成。
Transformer编码器
- 输入预处理:
- 将输入单词/标记(例如法语单词)映射到文本嵌入/向量中。
- 添加输入单词的位置编码信息。
- 编码器:
- 使用注意机制将预处理中的输入向量映射到上下文向量中。
- 上下文向量通过前馈层生成编码器输出。
- 由于注意机制,编码器输出比输入向量具有更好的表示,因为它们利用了其他输入标记的上下文信息。
Transformer解码器
- 输出预处理:
- 将输出单词/标记(例如英文单词)映射到文本嵌入中。
- 添加输出单词的位置编码信息。
- 解码器:
- 输出掩蔽自注意力:将输出向量映射到输出单词(例如英文单词)的上下文向量中。掩蔽用于在训练期间隐藏看不见的单词。
- 编码器解码器自注意力(或交叉注意力):在自注意力阶段的上下文向量(例如英文单词)和编码器输出(例如法语单词)之间执行交叉注意力。
- 结果向量通过前馈层生成解码器输出。
- 解码器输出利用(1)英文单词的自注意力和(2)法语-英文单词交叉注意力来获得更好的表示。
- 输出后处理:
- 使用 Softmax 函数将解码器输出映射到概率中以生成下一个输出单词(即英文单词)。