视频压缩和标准
视频编码和标准
视频压缩基础知识
空间冗余(spatial redundancy)是指图像内(或更具体地说,在小的图像邻域内)像素之间的统计相关性,也被称为帧内冗余(intraframe redundancy)。
时间冗余(temporal redundancy)是指视频序列中连续帧的像素之间的统计相关性,因此,它也被称为帧间冗余(interframe redundancy)。
心理视觉冗余(Psychovisual Redundancy)
- 频率掩蔽(frequency masking):人类对高频成分中的噪声或失真不太敏感,反之亦然。
- 色彩掩蔽(color masking):人类对亮度成分比色度成分更敏感。
视频压缩的方法:
- 通过利用视频中的冗余。
- 空间冗余。
- 时间冗余。
- 心理视觉冗余。
- 通过提高编码效率:
- Huffman编码。
- 预测/差分编码。
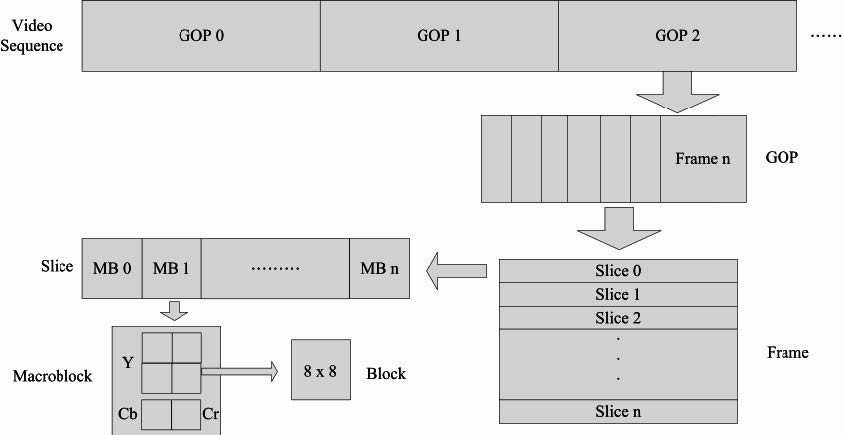
视频结构
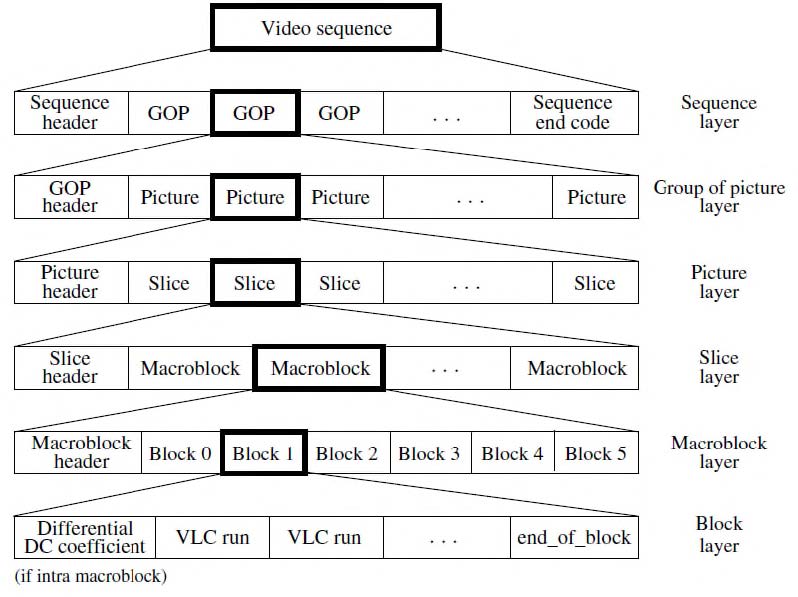
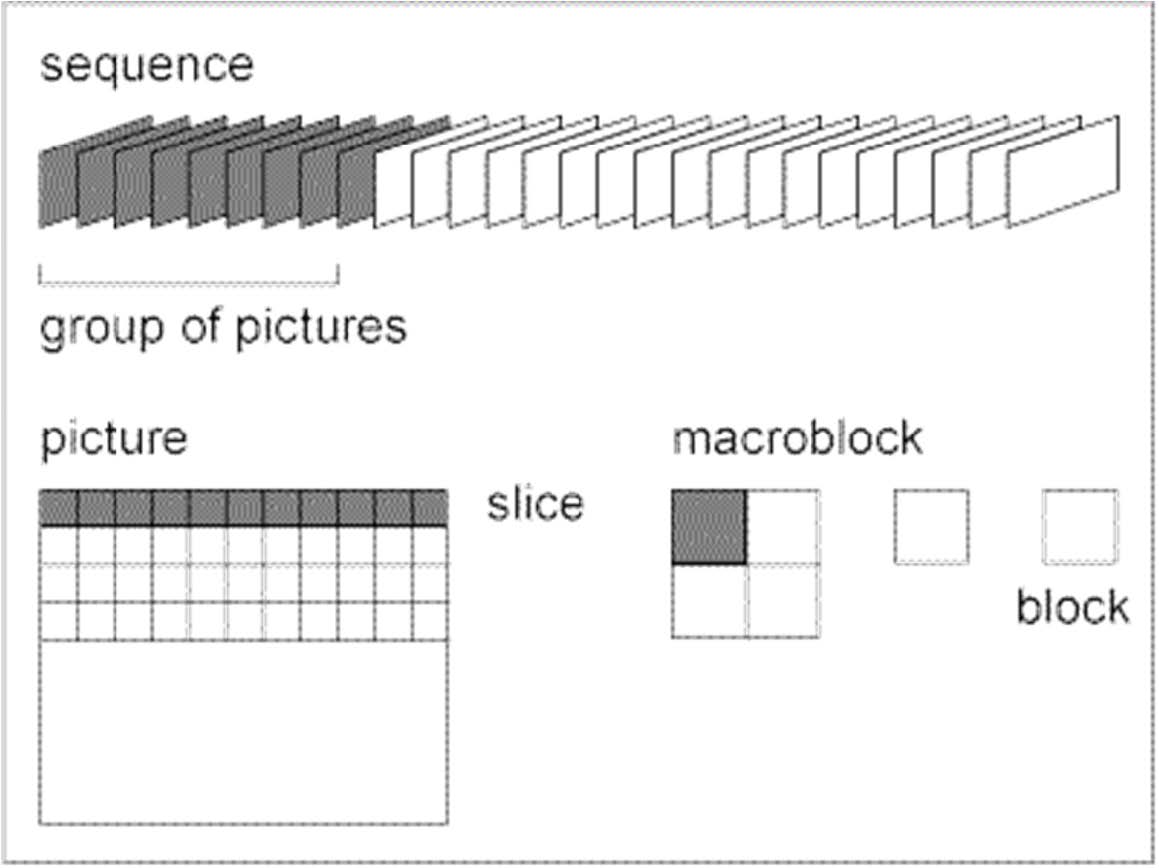
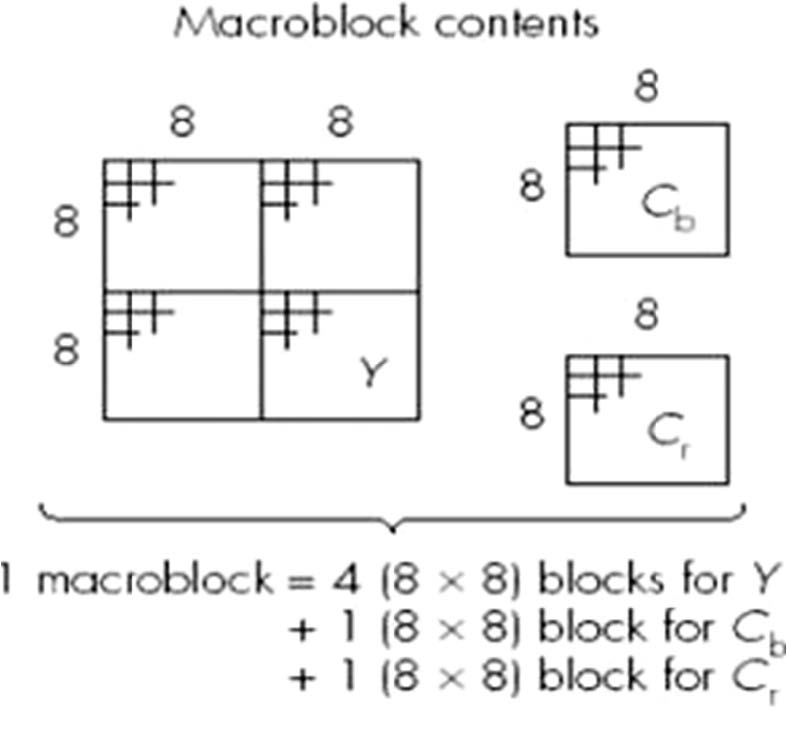
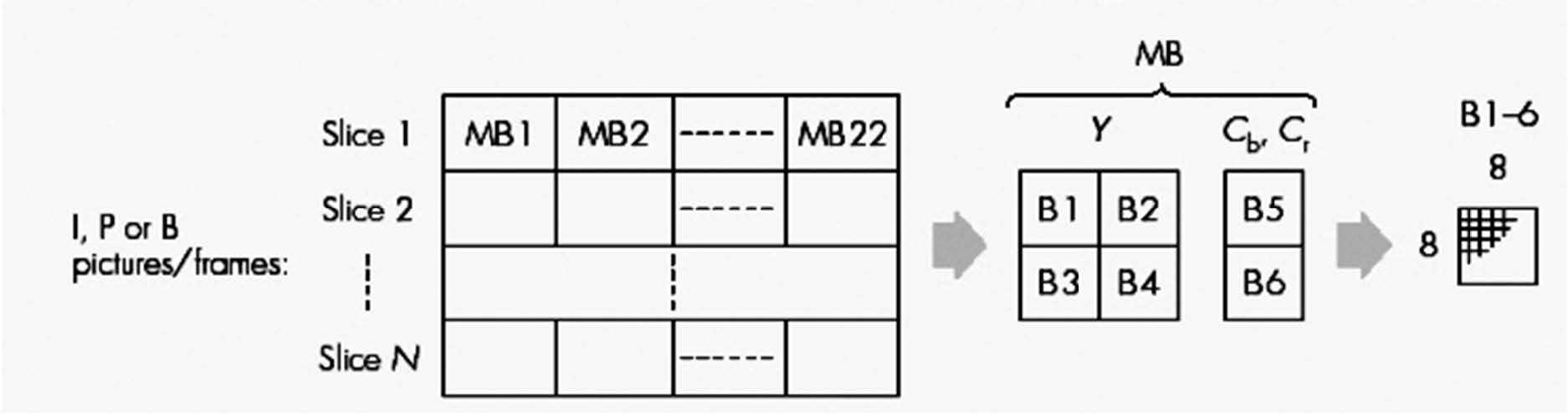
宏块(Macroblock)
一个宏块包含一个16x16的Y分量以及空间对应的8x8的Cb和Cr分量。
一个宏块有4个亮度块和2个色度块,是进行DCT运算和运动补偿的基本单位。
视频压缩基础知识
视频压缩的主要思想:
- 运动估计:预测宏块的运动矢量
- 运动补偿:对预测宏块和实际宏块之间的微小差异进行编码
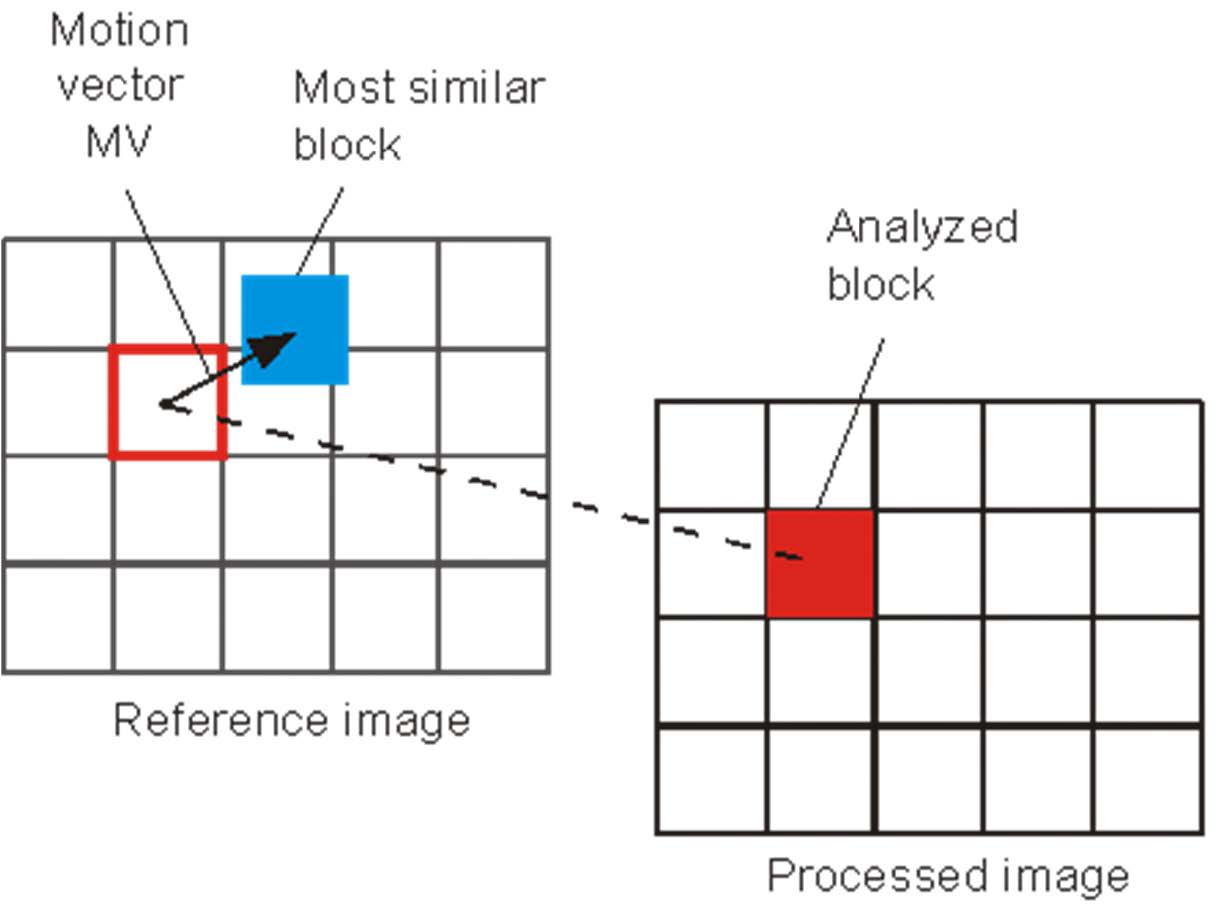
运动估计与补偿
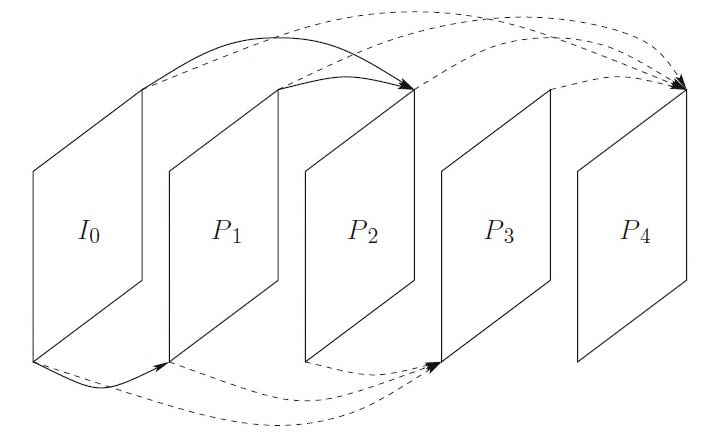
帧内压缩与帧间压缩
许多视频压缩方法(例如MPEG)都使用帧内压缩和帧间压缩。
帧内压缩
- 将每个视频帧视为静止图像(例如,MPEG中的I帧)。
- 减少空间冗余。
- 采用基于JPEG的压缩。
帧间压缩
- 利用时间域相关性(例如MPEG中的P帧和B帧)。
- 减少时间冗余。
- 采用运动估计和补偿。
色度二次采样(Chroma Subsampling)
二次采样格式:
- 4:4:4 - 无二次采样
- 4:2:2、4:1:1 - 水平二次采样
- 4:2:0 - 水平和垂直二次采样
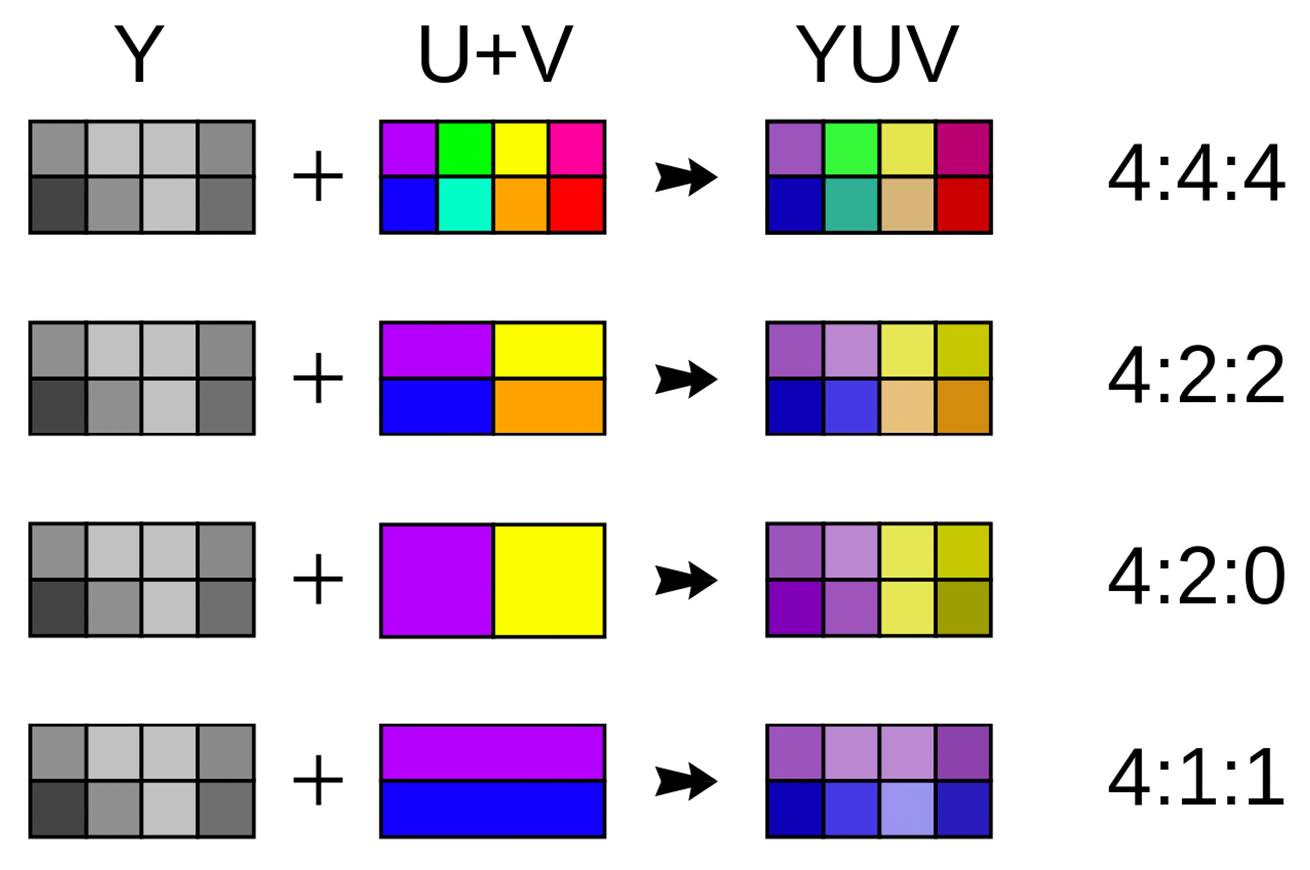
- 人类对亮度分量比色度分量更敏感。因此,为了实现压缩,色度分量被进行二次采样。
- 4:2:2二次采样:对于每两个水平Y样本,采样1个Cb和1个Cr。
- 4:2:0二次采样:对于每2x2的Y样本,采样1个Cb和1个Cr。
MPEG基础
-目的:对视频信号进行编码/压缩。 - MPEG标准基于DCT编码和运动估计与补偿。 - DCT编码:消除帧内冗余。 - 运动估计与补偿:消除帧间冗余。 - 彩色视频源有三个分量 - 亮度分量(Y) - 两个色度分量(Cb和Cr),通常采用4:2:0二次采样格式。
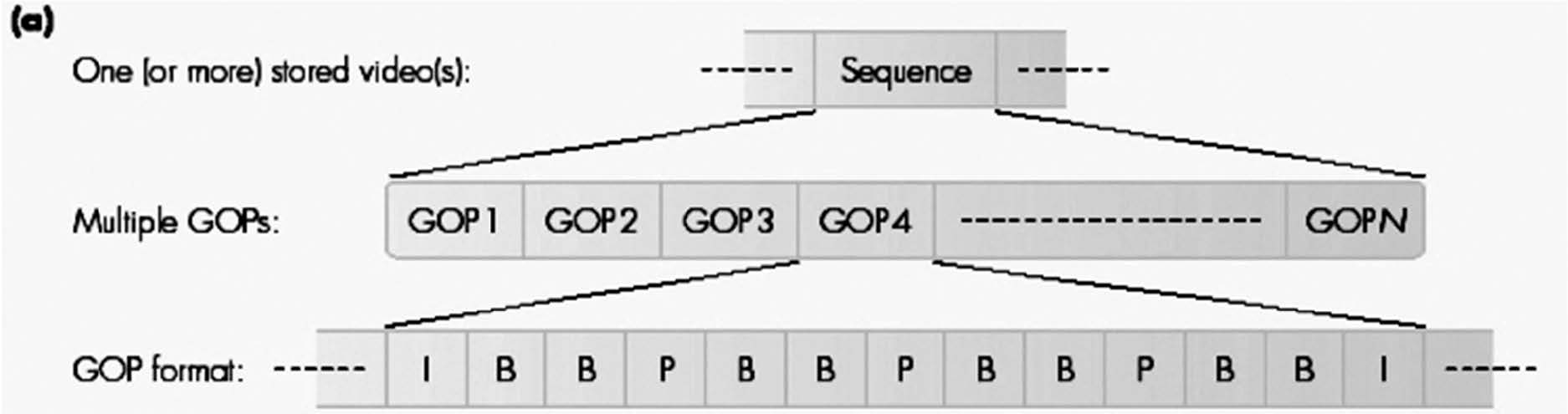
图片组(GOP)
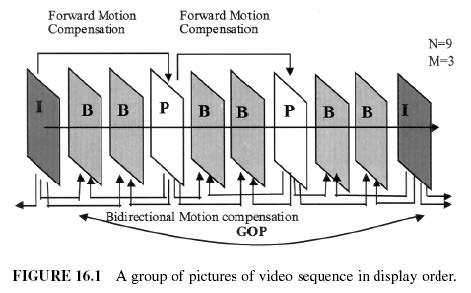
视频序列被划分为图像组(GOP)。
每个GOP可能包含三种类型的图片:
- I帧(帧内编码帧,Intra-coded frames)
- P帧(预测编码帧,Predictive-coded frame)
- B帧(双向编码帧,Bidirectional-coded frame)
I帧、P帧、B帧
- I帧
- 编码时不参考任何其他帧。
- Y、Cb、Cr块使用JPEG算法独立编码。
- P帧和B帧
- 称为帧间编码或插值帧。
- P帧使用来自前一个锚I帧或P帧的运动估计和补偿进行编码。
- B帧使用来自过去、未来或两个锚帧的预测进行编码。
运动估计与补偿
时间冗余:视频中连续的帧是相似的。
- 并非视频的每一帧都需要单独编码。
- 思路:对当前帧和序列中其他帧之间的差异进行编码。
- 差异值较小,因此有利于压缩。
- 视频压缩:
- 运动估计:运动矢量搜索。
- 运动补偿:计算预测误差。
运动估计
MV搜索通常仅限于小范围的邻近区域。水平和垂直位移都在\([−p,p]\)范围内。这使得搜索窗口的大小为\((2p+1)\times(2p+1)\)。
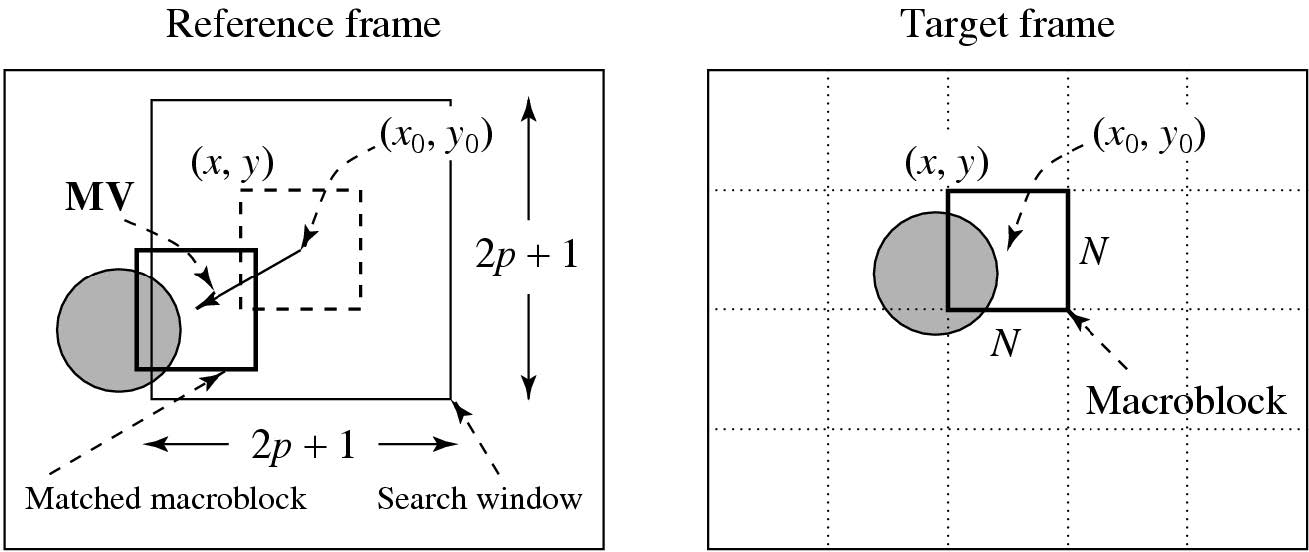
两个宏块之间的差异可以通过平均绝对差异(Mean Absolute Difference,MAD)来测量:
\[\mathrm{MAD}(i,j)=\frac1{N^2}\sum_{k=0}^{N-1}\sum_{l=0}^{N-1}\left\lvert C(x+k,y+l)-R(x+i+k,y+j+l)\right\rvert\]
- \(N\):宏块的大小
- \(k\)和\(l\):宏块中像素的索引
- \(i\)和\(j\):水平和垂直位移
- \(C(x+k,y+l)\):目标帧宏块中的像素
- \(R(x+i+k,y+j+l)\):参考帧宏块中的像素
目标:找到运动矢量\(\mathrm{MV}=(u,v)\),使得\(\mathrm{MAD}(i,j)\)最小:
\[(u,v)=\arg\min_{(i,j)}\mathrm{MAD}\ ,i\in[-p,p],j\in[-p,p]\]
运动估计方法
- 全面搜索
- 三步搜索
- 2D-Log 搜索
- 分层搜索
- 钻石搜索
- 交叉搜索
- 等等
全面搜索
- 搜索搜索窗口内的每个点。
- 优点:准确、压缩率最高。
- 缺点:速度慢、计算量大。
三步搜索
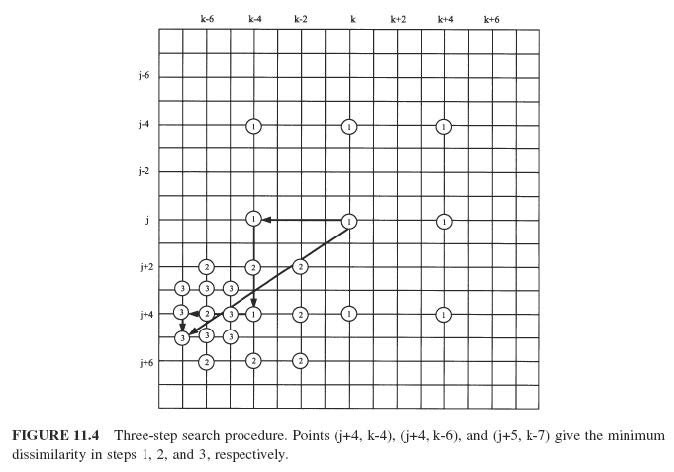
仅包含 3 个步骤。
- 步骤 1:搜索 9 个点以获得最小预测误差。
- 步骤 2:以步骤 1 中找到的位置为中心,将搜索宽度减半,搜索 9 个点以获得最小误差。
- 步骤 3:以步骤 2 中找到的位置为中心,将搜索宽度减半,搜索 9 个点以获得最小误差。最终位置是找到的最佳位置。
- 优点:快速
- 缺点:准确度较低,压缩率较低。
二维对数搜索
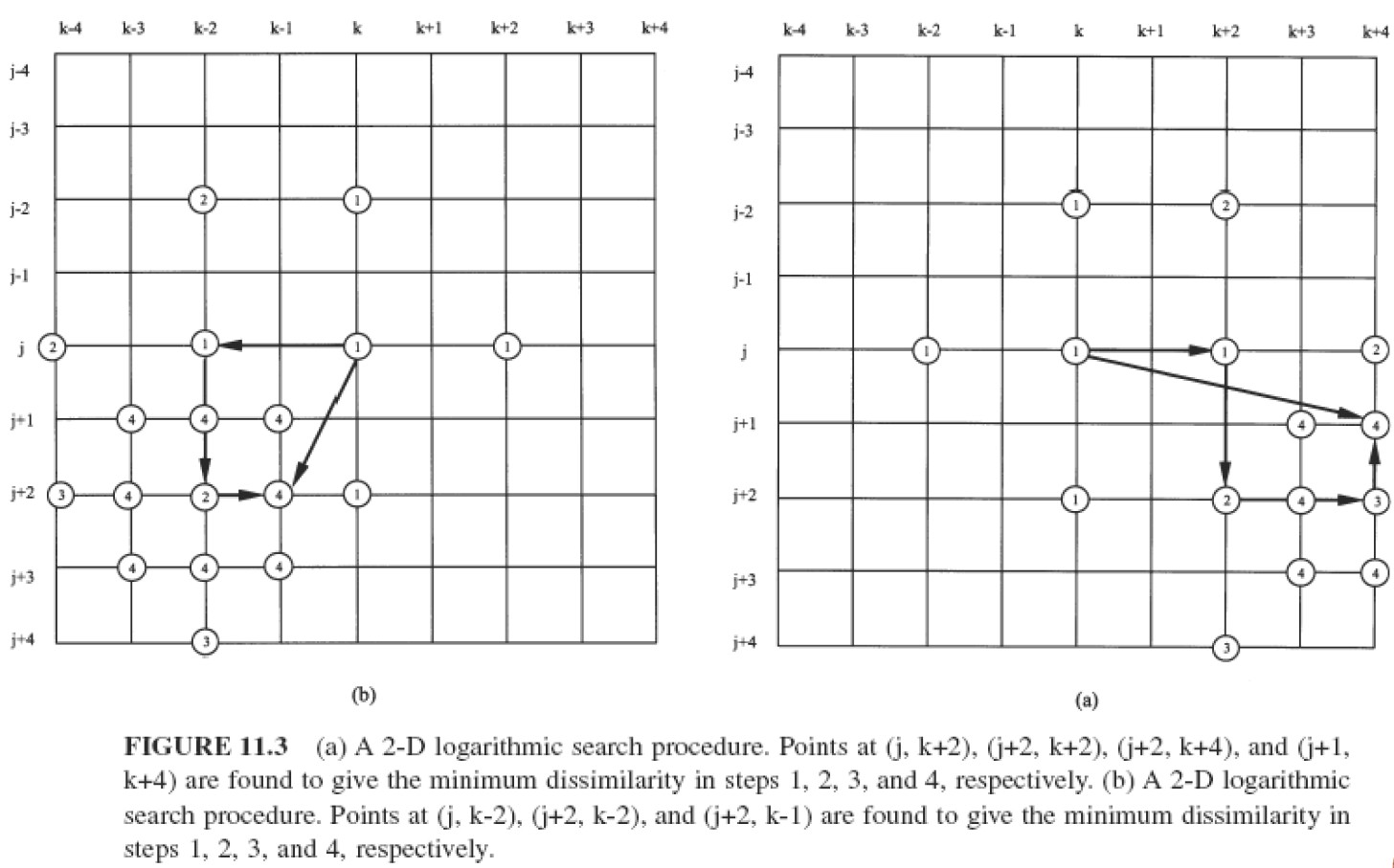
- 步骤 1:搜索 5 个点以获得最小预测误差。
- 步骤 2:以前次迭代中找到的位置为中心,
- 如果找到的位置是中心位置或位于边界,则将搜索宽度减半;否则,保留搜索宽度。
- 如果搜索窗口尚未达到 3x3,则搜索 5 个点以获得最小误差并重复步骤 2。
- 否则,如果搜索窗口为 3x3,则搜索 9 个点以获得最小误差并返回最佳找到位置。
- 速度:介于完整搜索和 3 步搜索之间。
- 准确度:介于完整搜索和 3 步搜索之间。
分层搜索
- 三级分层搜索,原始图像位于第 0 级。
- 第 1 级和第 2 级的图像是通过从前面的级别按 2 倍的倍数下采样获得的,初始搜索在第 2 级进行。
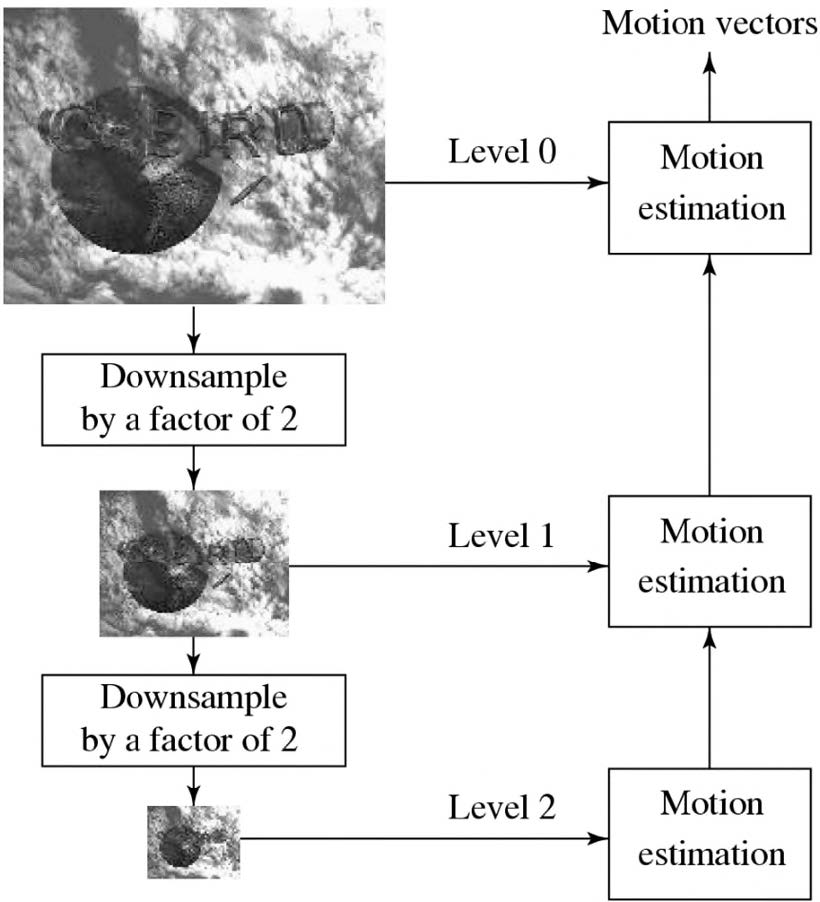
- 搜索可从分层/多分辨率方法中受益。
- 可以从分辨率显著降低的图像中获得运动矢量的初始估计。
- 宏块的尺寸更小。
- 搜索范围 p 也可按比例缩小。
- 因此,所需的操作数量大大减少。
MPEG标准
MPEG-1
- 由 ISO/IEC 于 1992 年 11 月制定。
- 有损视频/音频压缩标准。
- 为数字存储媒体 (VCD) 提供速度为 1.5 Mbps 的视频及其相关音频编码。
- JPEG、H.261 的扩展。
- 仅支持逐行扫描。
- 支持的图片分辨率:
- 30 fps 的 NTSC 视频为 352 × 240。
- 25 fps 的 PAL 视频为 352 × 288。
- 使用 4:2:0 色度子采样。
MPEG-1 也称为 ISO/IEC 11172。
它有五个部分:
- 第 1 部分 - MPEG-1 系统
- 第 2 部分 - MPEG-1 视频
- 第 3 部分 - MPEG-1 音频
- 第 4 部分 - 一致性
- 第 5 部分 - 参考软件
限制:
- 仅支持逐行扫描。
- 图像质量低。
- 压缩率低。
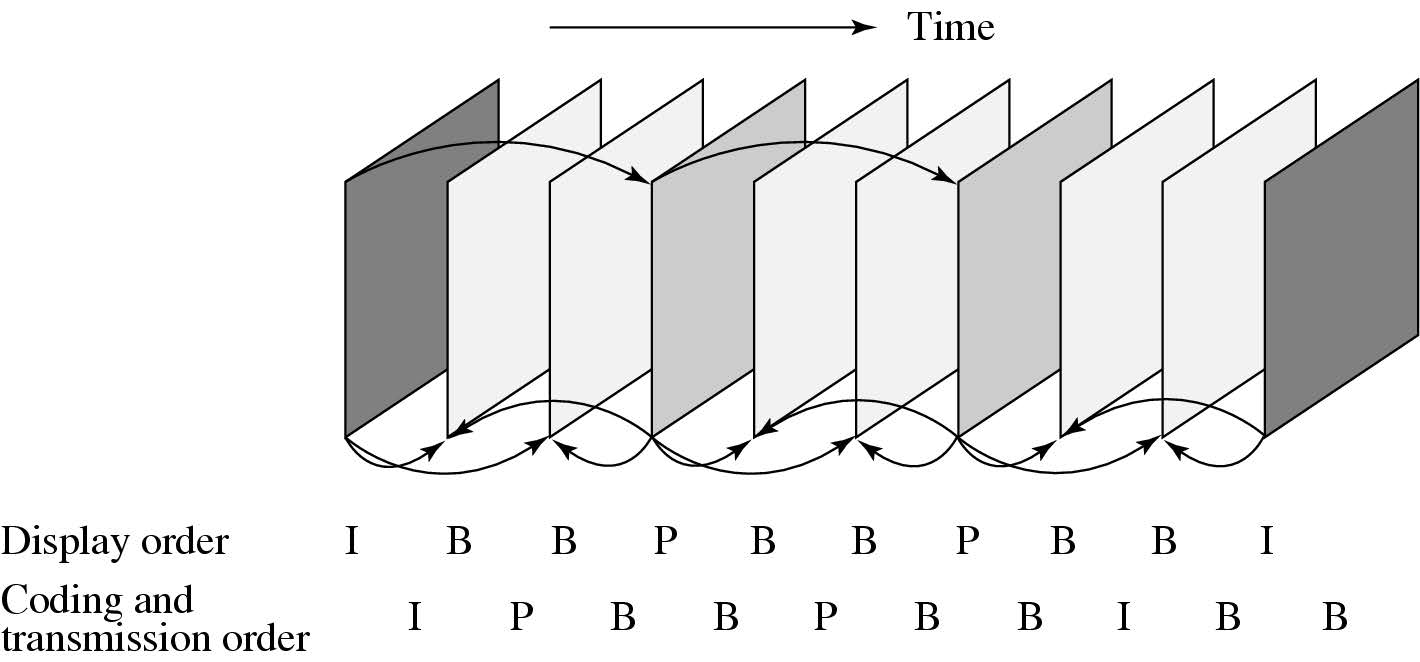
I、P 和 B 帧编码
I帧编码

P帧编码
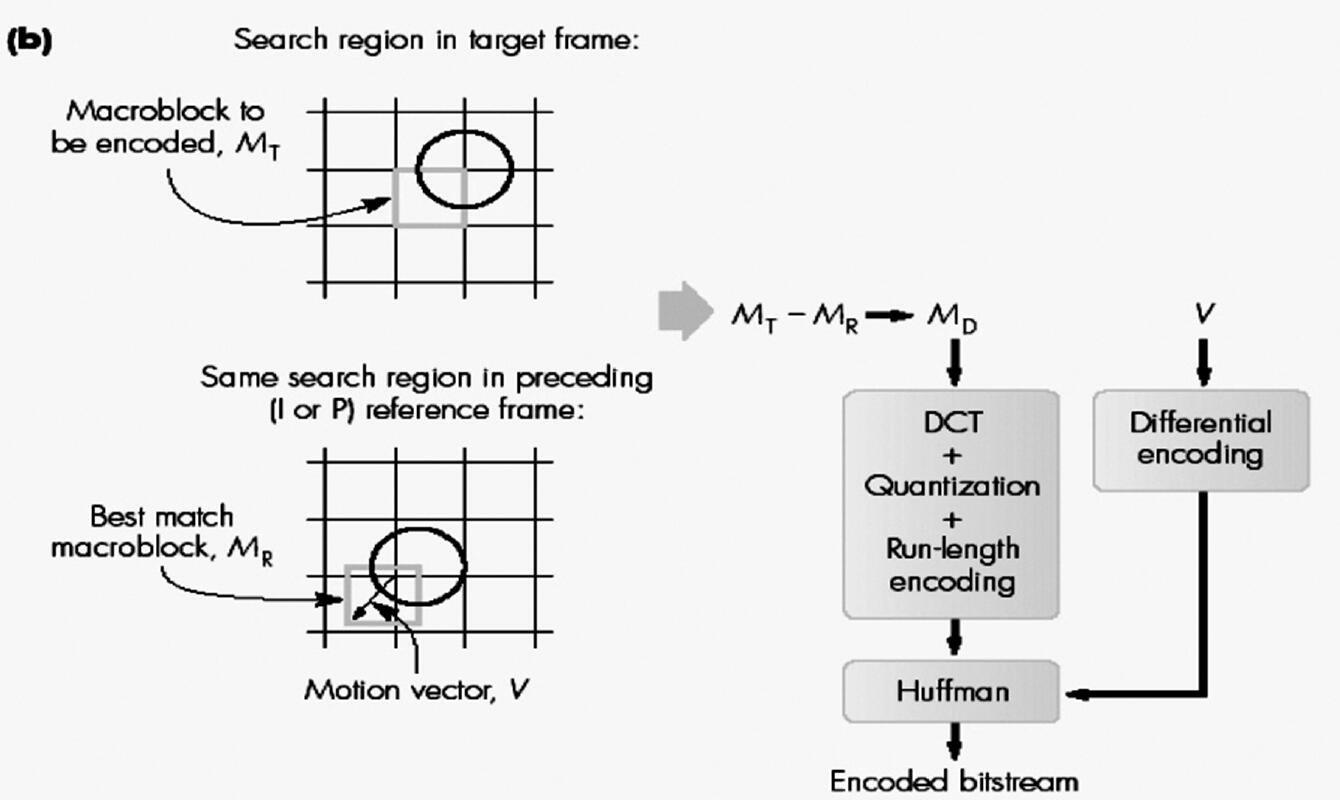
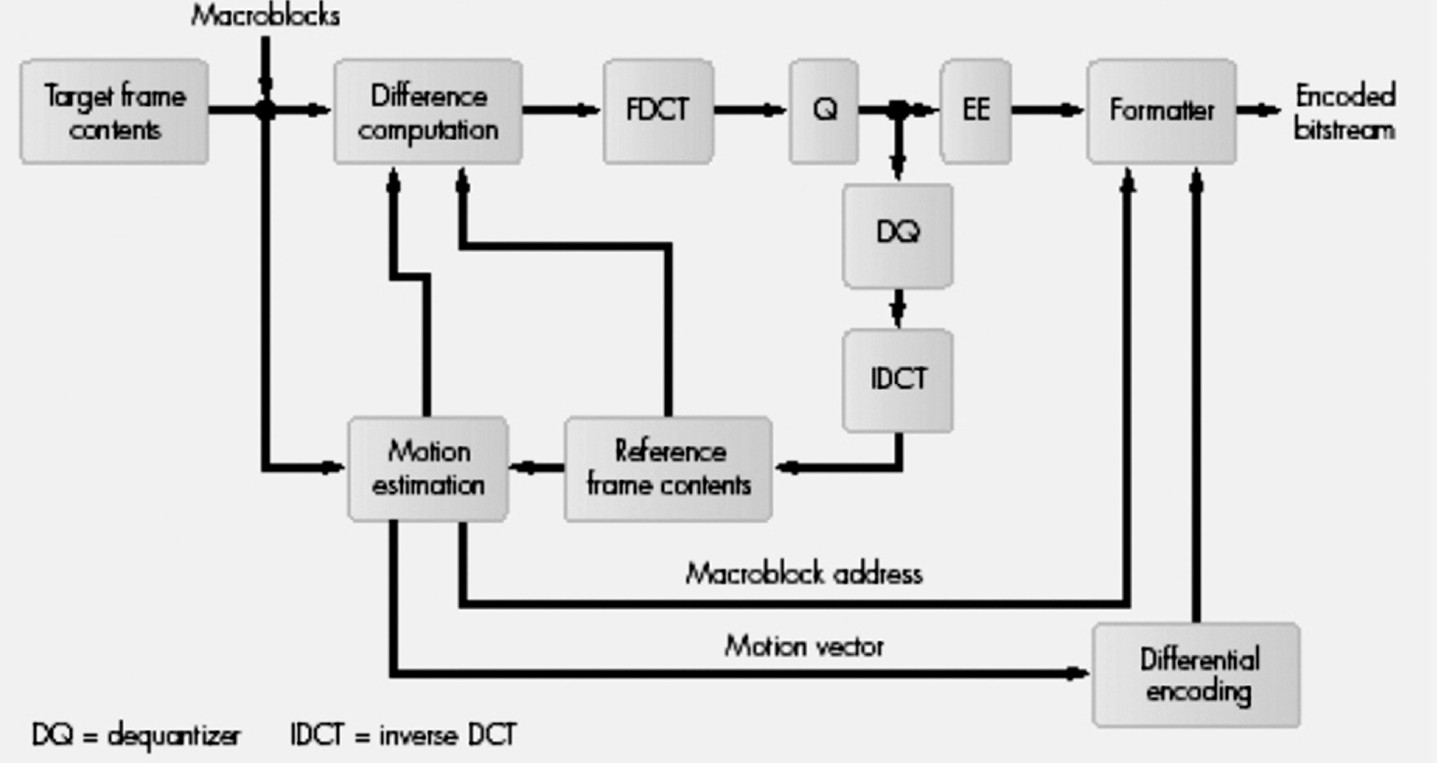
- 对目标帧中的每个宏块进行运动估计和补偿。
- 将目标帧中的每个宏块与前一个I或P参考(锚)帧进行比较。
- 对于每个宏块,以参考帧中的搜索窗口为中心进行搜索。
- 如果绝对差和(SAD)小于阈值,则找到匹配项。
- 如果找到匹配项,则确定两个参数:运动矢量和预测误差(矩阵)。
- 运动矢量测量目标宏块的位置与参考帧中最佳匹配宏块的位置之间的偏移或位移矢量。
- 预测误差测量目标宏块与参考帧中最佳匹配宏块之间的差异(矩阵)。
- 运动矢量使用差分编码进行编码,并对得到的符号进行霍夫曼编码。
- 预测误差(Y、Cr、Cb)的差异矩阵使用与 I 帧相同的步骤进行编码。
- 如果未找到匹配项,则将宏块独立编码为 I 帧中的宏块。
B帧编码
为什么双向搜索:
- 在前一个和下一个参考帧中找到目标帧的宏块 (MB) 的良好匹配的几率更高。
- 例如,目标帧中包含球的一部分的 MB 无法在前一帧中找到良好的匹配 MB。
- 但是,可以从下一帧轻松获得匹配。
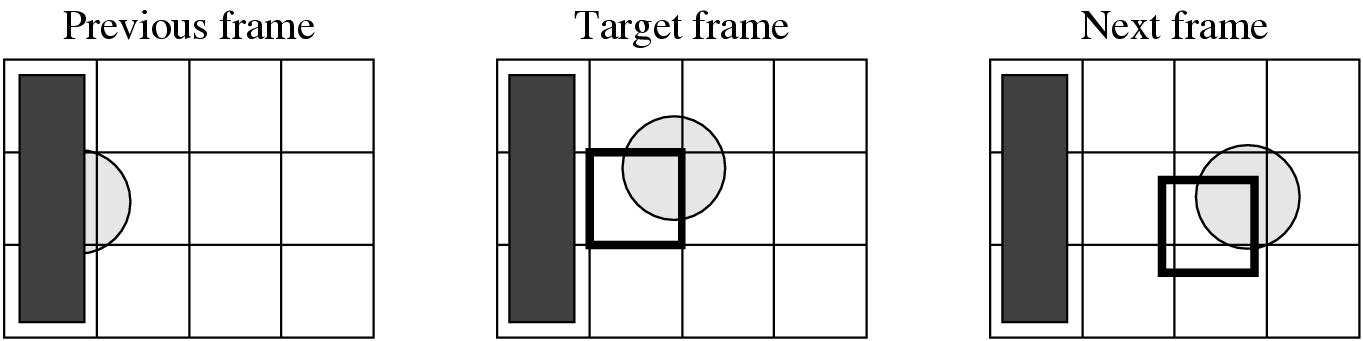
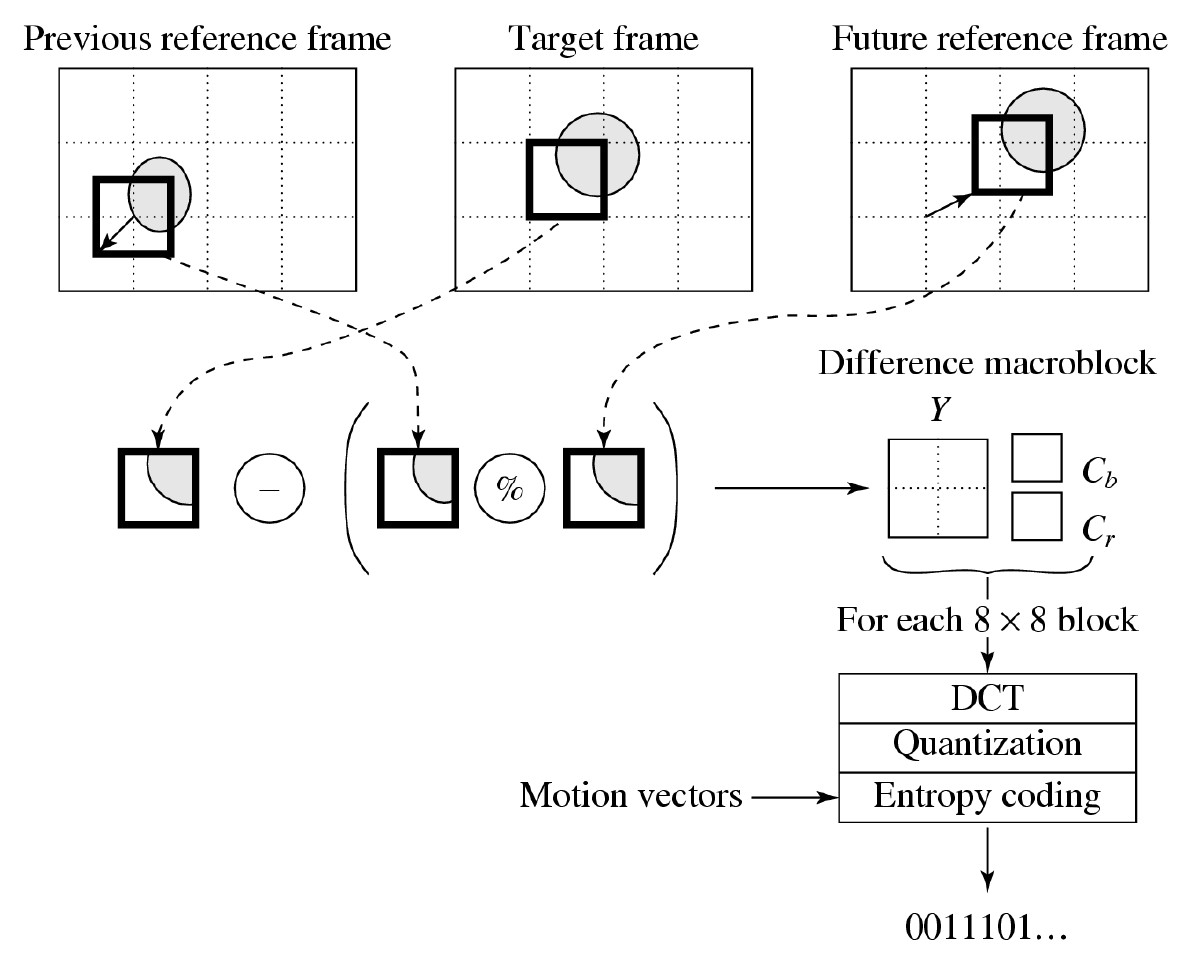
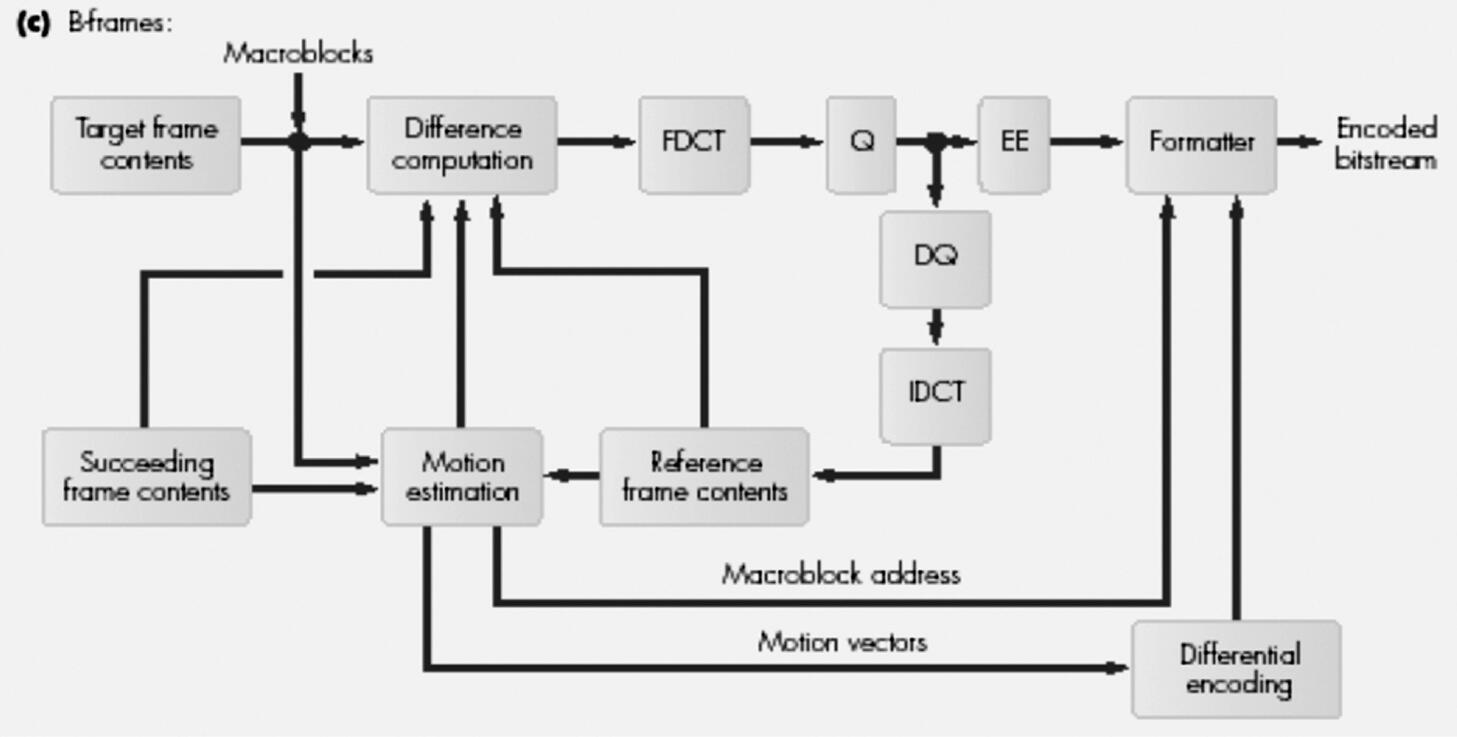
- 对于目标帧中的每个宏块,针对前一个(前一个)和后一个(后一个)参考(锚点)I 帧或 P 帧执行运动估计和补偿。
- 这会产生 2 组(运动矢量、差异矩阵)对,一组基于前一个锚点帧,另一组基于后一个锚点帧。
- 使用目标宏块以及前一个和后一个最佳匹配宏块的平均值计算第三个差异矩阵。
- 选择具有最小预测误差的集合,并以与 P 帧相同的方式对其进行编码。
帧大小
- P帧明显小于I帧,因为利用了时间冗余。
- B帧甚至比P帧还要小,因为具有双向预测的优势。
MPEG-2
- 旨在解决 MPEG-1 的局限性:例如,低比特率(1.5 Mbps)、仅逐行扫描。
- 1995 年标准化。
- 为高比特率(4 Mbps)的数字广播电视(隔行扫描)开发。
- 为不同的应用定义不同的配置文件。
- 支持可扩展编码。
可扩展性
可扩展编码对于通过具有以下特征的网络传输的MPEG-2视频非常有用:
- 比特率差异很大的网络。
- 具有可变比特率 (VBR) 通道的网络。
- 具有噪声连接的网络。
可扩展编码
- 分层编码:一个基础层和一个或多个增强层。
- 基础层可以独立编码、传输和解码以获得基本视频质量。
- 首先发送基础层的比特流,以便为用户提供快速和基本的视频视图,然后发送增强层以提高质量。
- 但是,增强层的编码和解码依赖于基础层或先前的增强层。
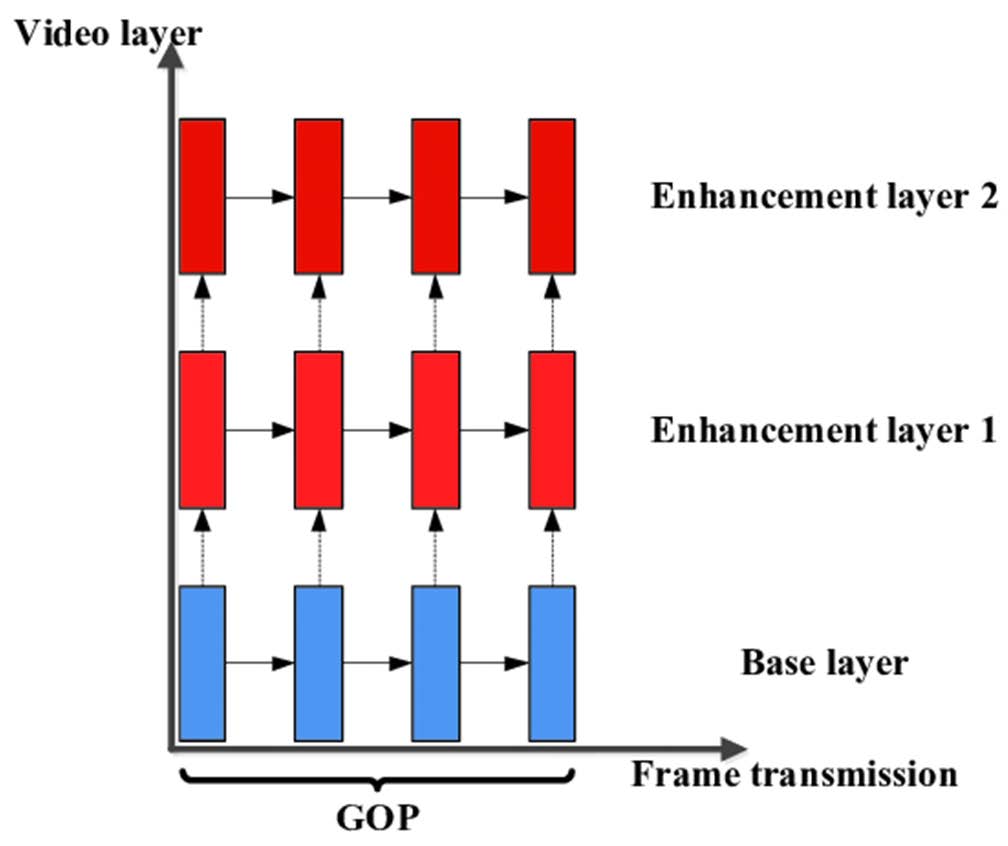
可扩展性种类

- SNR可扩展性:增强层提供更高的SNR。
- 空间可扩展性:增强层提供更高的空间分辨率。
- 时间可扩展性:增强层有助于提高帧速率。
- 混合可扩展性:这结合了上述三种可扩展性中的任意两种。
- 数据分区:量化DCT系数被分成多个分区。
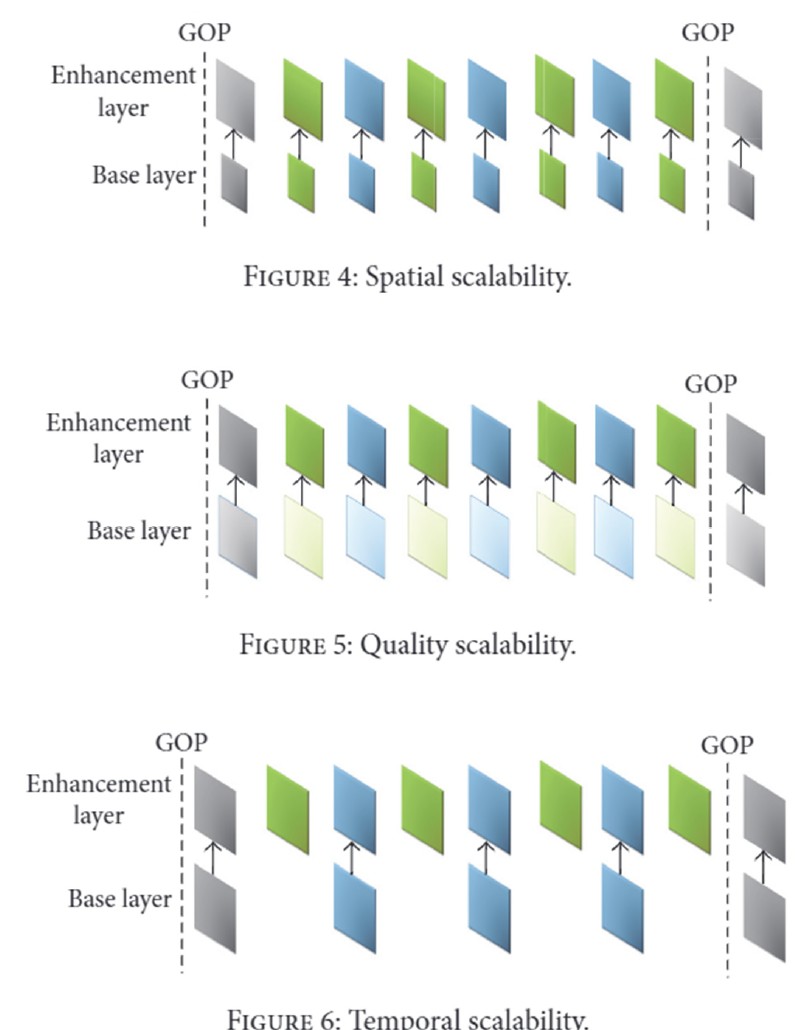
SNR可扩展性
- 对基础层进行增强以提高信噪比(SNR)。
- 在两层生成输出比特流Bits_base和Bits_enhance:
- 基础层对DCT系数进行粗量化,导致位数较少且视频质量相对较低。
- 粗量化的DCT系数随后进行逆量化(Q-1)并馈送到增强层以与原始DCT系数进行比较。
- 它们的差异被精细量化以生成DCT系数细化,经过VLC后,变为称为Bits_enhance的比特流。
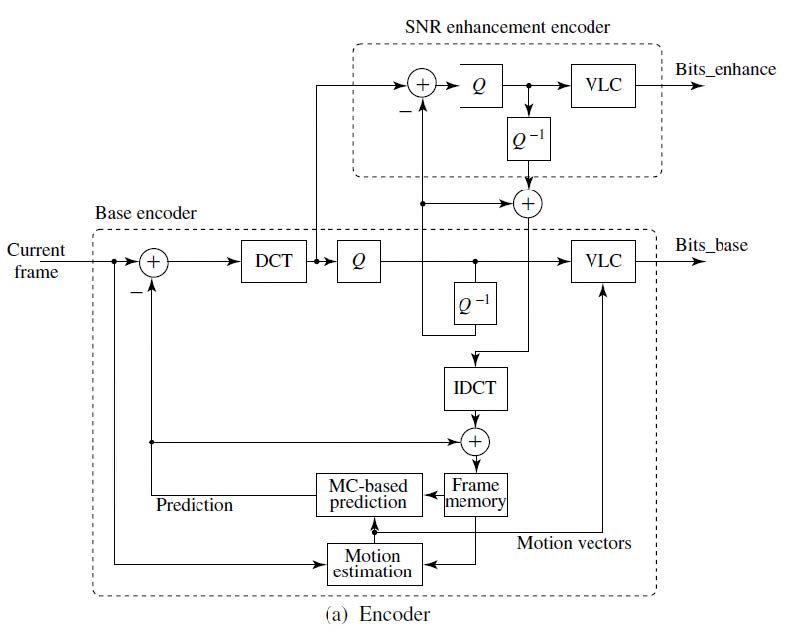
空间可扩展性
- 基础层用于生成降低分辨率图片的比特流。
- 与增强层结合时,生成原始分辨率的图片。
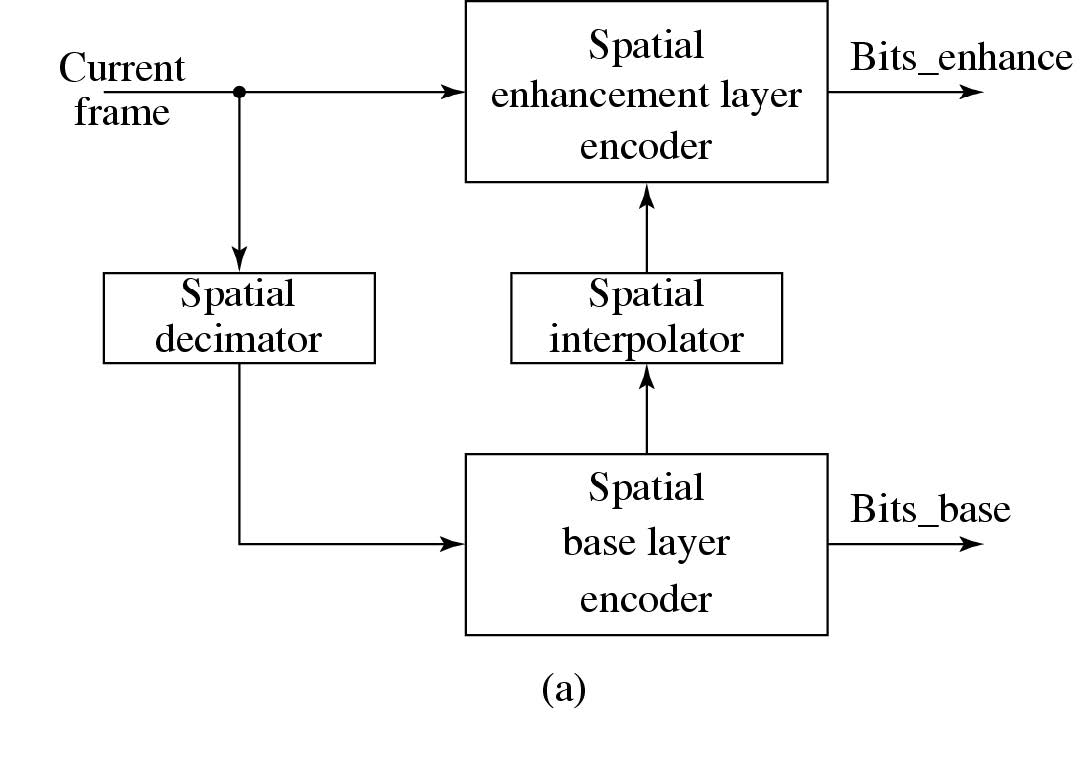
时间可扩展性
- 输入视频在时间上被解复用为两部分,每部分承载原始帧速率的一半。
- 基础层编码器对其自己的输入视频执行正常的单层编码程序,并产生输出比特流 Bits_base。
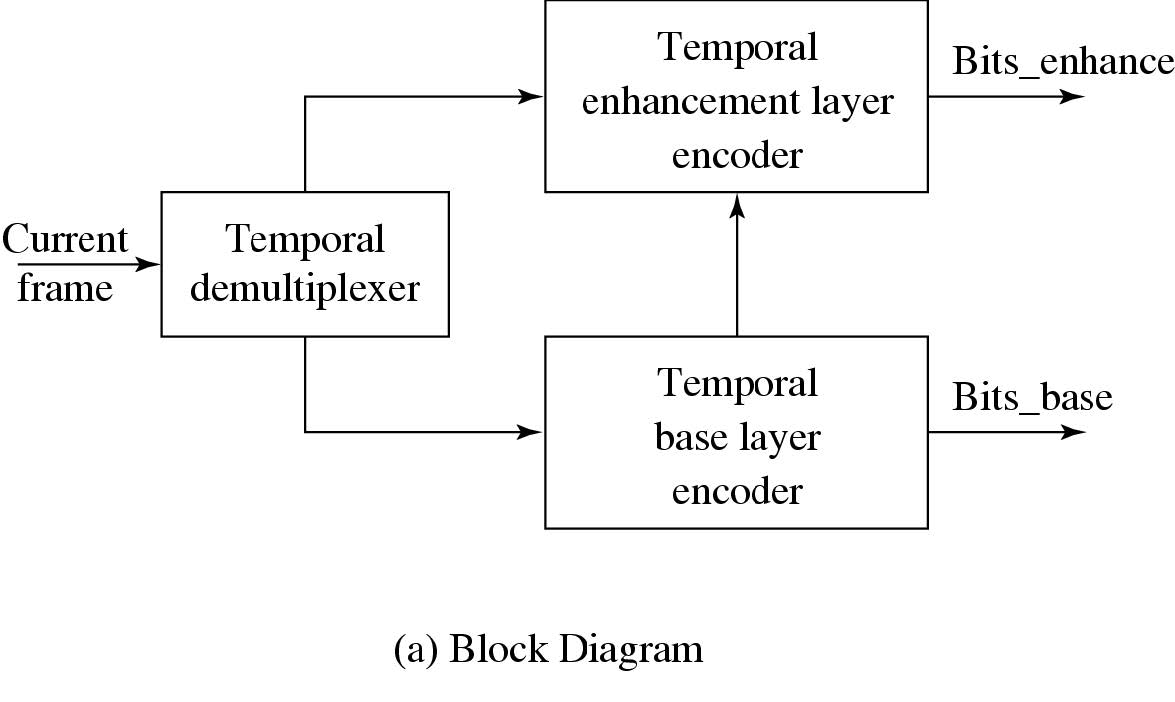
混合可扩展性
- 以上三种可伸缩性中的任意两种可以组合形成混合可伸缩性:
- 空间和时间混合可伸缩性。
- SNR和空间混合可伸缩性。
- SNR和时间混合可伸缩性。
- 通常采用由基础层、增强层1和增强层2组成的三层混合编码器。
数据分区
- 基础分区包含低频DCT系数。
- 增强分区包含高频DCT系数。
- 严格来说,数据分区不是分层编码:
- 因为单个视频数据流被简单地分割。
- 在生成增强分区时不再依赖基础分区。
- 适用于通过嘈杂的信道进行传输和渐进式传输。
相对于MPEG-1的优势
- 在同等比特率下,图像质量比MPEG-1更好。
- 支持逐行和隔行扫描,而MPEG-1仅支持逐行扫描。
- 支持可扩展性,而MPEG-1不支持。
- 更好地抵御比特错误。MPEG-2可以在嘈杂且不可靠的网络上传输带有比特错误的视频。
- 支持 4:2:2 和 4:4:4 色度子采样以提高色彩质量。
- 更灵活的视频格式,支持DVD和HDTV定义的各种图像分辨率。
H.26x标准
H.264
- 2003年由ITU-T VCEG和ISO/IEC MPEG标准化。
- 也称为高级视频编码(AVC)或MPEG-4第10部分。
- 压缩效率比H.262高50%,比H.263高30%。
- 应用:互联网视频、计算机、高清电视广播、蓝光盘、移动和便携式设备。
- 通过可变块大小、多参考帧改进运动补偿。
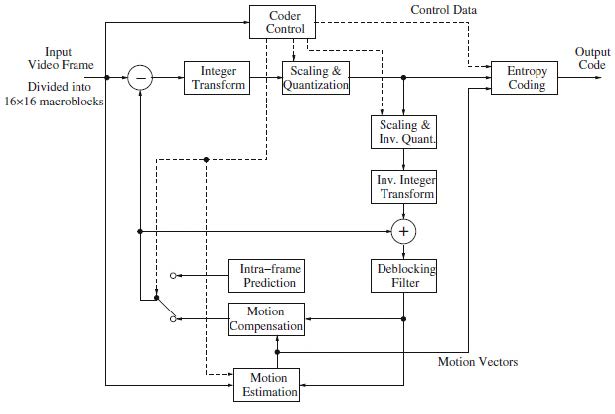
主要特点
- 4×4块中的整数变换。低复杂度,无漂移。
- 可变块大小运动补偿,亮度图像中从16×16到4×4。
- 通过插值实现运动矢量的四分之一像素精度。
- 多参考图像运动补偿。
- 帧内方向空间预测。
- 循环内去块滤波。
- 上下文自适应可变长度编码 (CAVLC) 和上下文自适应二进制算术编码 (CABAC)
- 对数据错误和数据丢失更具鲁棒性。
- 采用混合编码
- 帧内空间预测。
- 帧间运动预测。
- 对残差进行变换编码。
运动补偿
- 可变块大小运动补偿。
- 两种类型:16×16宏块(M类型)和8×8分区(8×8类型)。
- 默认情况下,宏块的大小为 16×16。
- 可以进一步划分为更小的分区。
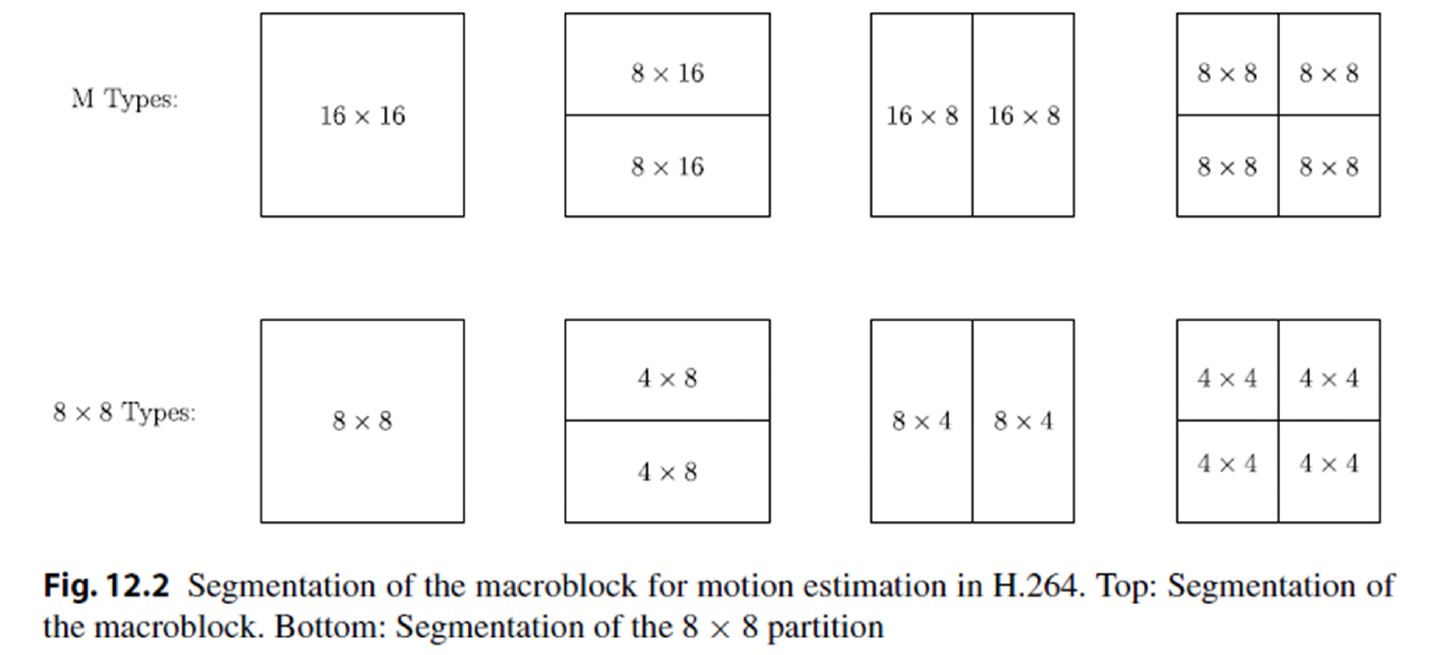
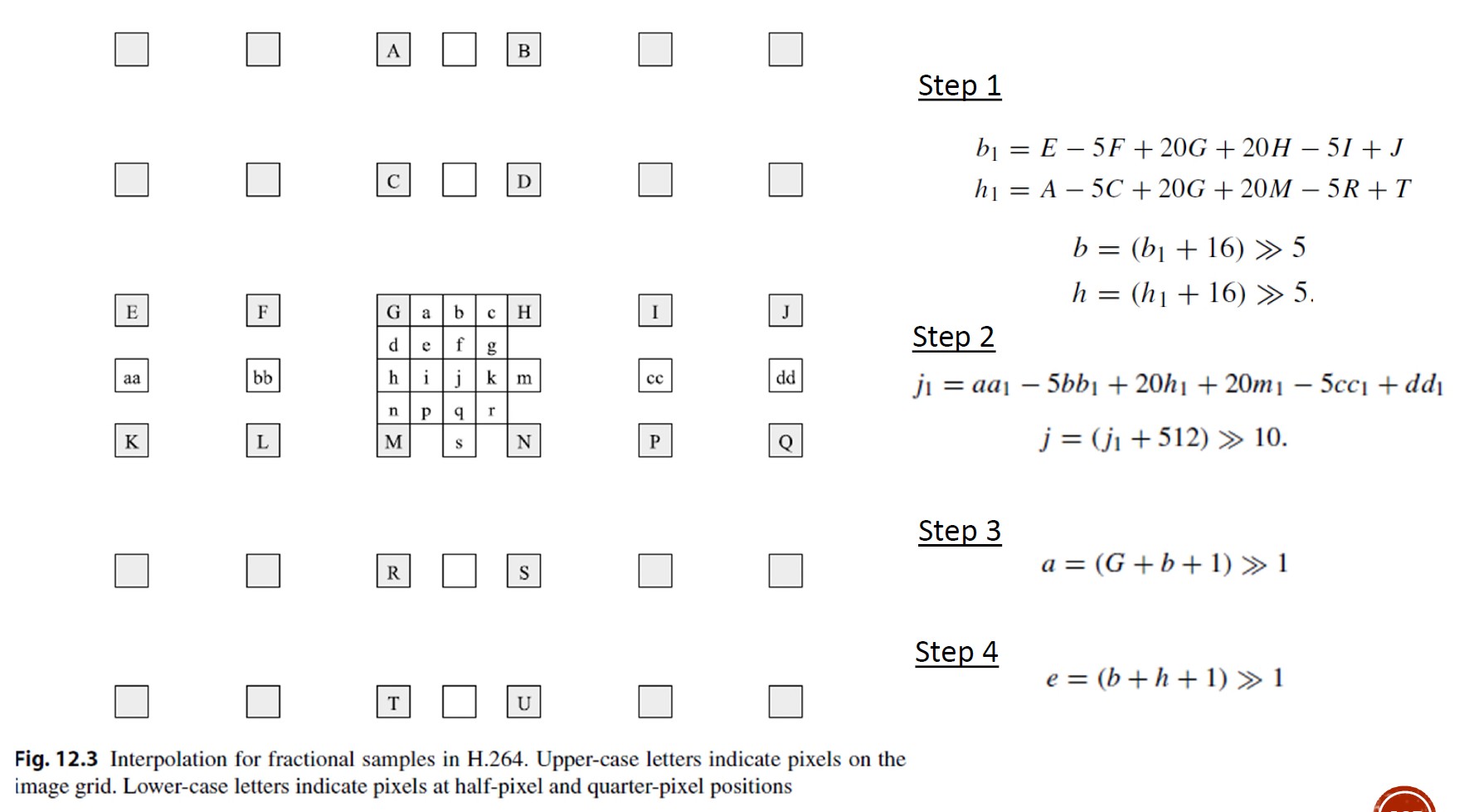
- 在亮度图像中,运动补偿的精度为四分之一像素精度。
- 半像素和四分之一像素位置的像素值可以通过插值得出。
- 使用6抽头滤波器估算半像素位置的像素值(b和h):
\[ \begin{aligned} b_1&=E-5F+20G+20H-5I+J\\ h_1&=A-5C+20G+20M-5R+T\\ \end{aligned} \]
\[ \begin{aligned} b&=(b_1+16)\gg5\\ h&=(h_1+16)\gg5\\ \end{aligned} \]
- 请注意,>>为按位右移。
- b 和 h 被剪裁到图像范围,例如 0-255。
GOP中的附加选项
- 无 B 帧
- B 帧中的宏块预测会导致更多延迟和存储。
- 在此选项中,仅允许 I 帧和 P 帧。
- 压缩效率相对较低。
- 更适合某些应用,例如视频会议。
- 与 H.264 的 Baseline Profile 或 Constrained Baseline Profile 兼容。
- 多个参考帧
- 为了在 P 帧中找到每个宏块的最佳匹配,H.264 最多允许 N 个参考帧。
- 提高压缩效率。
- 需要更多计算。
整数变换
DCT会因为浮点计算和变换与逆变换中的舍入误差而导致预测偏移。
它可能累积起来,导致较大的误差。
在H.264中,整数变换用于解决该问题。
H.264提供具有非线性步长的量化方案,以获得准确的速率控制。
2D DCT 可以通过两个连续的1D变换实现。
令\(\mathbf f\)为4×4输入矩阵,\(\mathbf F\)为DCT变换数据,\(\mathbf T\)为DCT矩阵:
\[ \mathbf F=\mathbf T\times\mathbf f\times\mathbf T^\intercal \]
- 4x4 DCT 矩阵由以下公式给出:
\[ \mathbf T_4= \begin{bmatrix} a&a&a&a\\ b&c&-c&-b\\ a&-a&-a&a\\ c&-b&b&-c \end{bmatrix}\\ \begin{cases} a=\frac12\\ b=\frac1{\sqrt2}\cos\frac\pi8\\ c=\frac1{\sqrt2}\cos\frac{3\pi}8 \end{cases} \]
为了导出缩放的4×4整数变换,我们可以简单地将\(\mathbf T_4\)的条目向上缩放并将它们四舍五入为最接近的整数
\[ \mathbf H=\mathrm{round}(\alpha\cdot\mathbf T_4) \]
设\(\alpha=2.5\),得到4x4整数DCT矩阵
\[ \mathbf H= \begin{bmatrix} 1&1&1&1\\ 2&1&-1&-2\\ 1&-1&-1&1\\ 1&-2&2&-1 \end{bmatrix} \]
- \(\mathbf H\)是正交的。但是,它的行不再具有相同的范数。
- 归一化步骤推迟到量化步骤。
- 逆变换:
\[ \mathbf H_{\mathrm{inv}}= \begin{bmatrix} 1&1&1&\frac12\\ 1&\frac12&-1&-1\\ 1&-\frac12&-1&1\\ 1&-1&1&-\frac12 \end{bmatrix} \]
- 令\(\mathbf f\)为4×4输入矩阵,\(\hat{\mathbf F}\)为量化变换输出。
- 正向整数变换,缩放和量化:
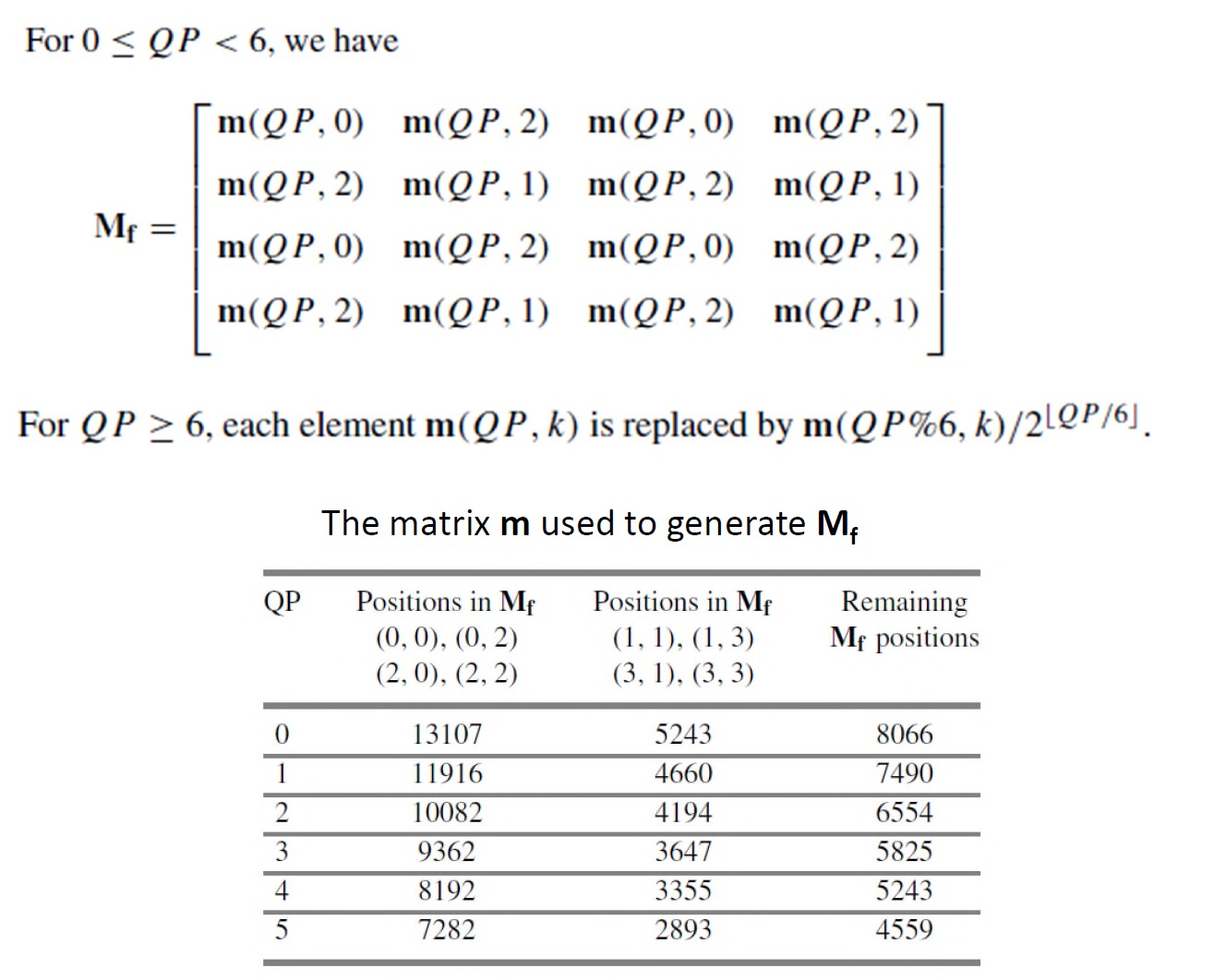
\[ \hat{\mathbf F}=\mathrm{round}\left[\left(\mathbf H\times\mathbf f\times\mathbf H^\intercal\right)\cdot\frac{\mathbf M_{\mathbf f}}{2^{15}}\right] \]
其中,“×”表示矩阵乘法,“·”表示元素乘法,\(\mathbf M_{\mathbf f}\)是由矩阵\(\mathbf m\)和量化参数QP得到的4×4量化矩阵。
令\(\hat{\mathbf f}\)为去量化然后逆变换的结果。缩放、去量化和逆整数变换为:
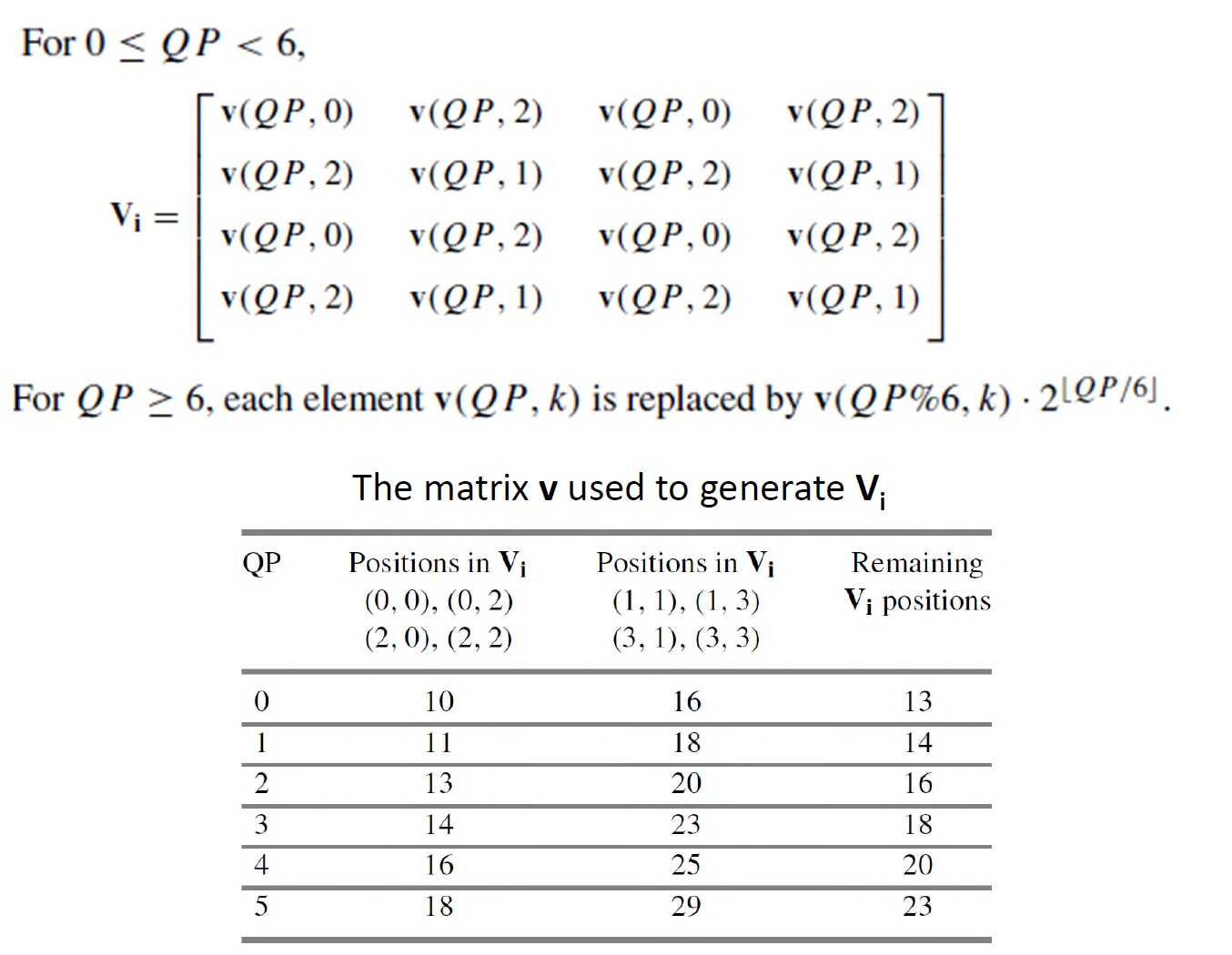
\[ \hat{\mathbf f}=\mathrm{round}\left[\frac{\mathbf H_{\mathrm{inv}}\times\left(\hat{\mathbf F}\cdot\mathbf V_i\right)\times\mathbf H_{\mathrm{inv}}^\intercal}{2^6}\right] \]
其中\(\mathbf V_i\)是由矩阵\(\mathbf v\)和量化参数QP得到的4×4反量化矩阵。
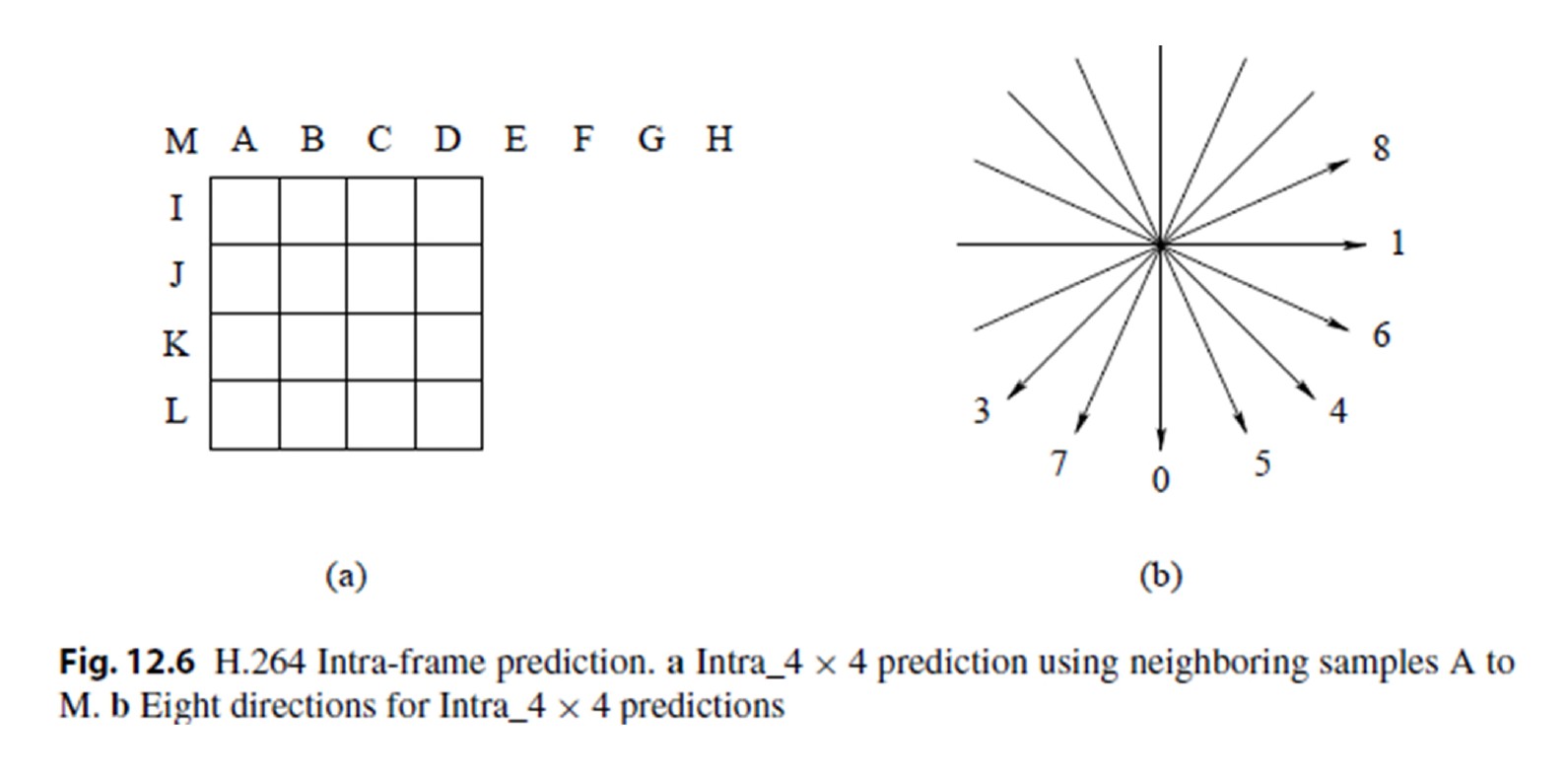
帧内编码
使用一些相邻的重建像素来预测帧内编码宏块。
可以选择不同的帧内预测块大小(4×4或16×16)。
4×4 块有九种预测模式。
16×16 块有四种预测模式。
对于每种预测模式,将比较预测值和实际值以产生预测误差/残差。
产生最小残差的模式将被选为该块的预测模式。
然后将残差发送到变换编码,其中采用 4×4 整数变换。

H.264比特流结构